L’umanità dell’internet
(le vie della rete sono infinite)
di Giancarlo Livraghi
gian@gandalf.it
Appendice 1
Che cos’è l’internet
e come funziona
Ovviamente queste spiegazioni sono inutili
per chi conosce bene la struttura della rete.
Ma, nonostante le montagne d’inchiostro
scritte sull’argomento, ci sono ancora
molte persone, colte e bene informate,
che non hanno un’idea chiara
di che cosa sia l’internet e come funzioni.
Ecco una breve sintesi dei fatti essenziali.
(Una “cronologia”dalle origini a oggi
si rtrova in un documento separato)
Come si è sviluppata l’internet
L’idea di un sistema che permettesse di collegare le reti telematiche si era diffusa all’inizio degli anni sessanta. Fra diversi progetti che si erano avviati, quello che portò alla nascita dell’internet nacque nel 1969 negli Stati Uniti per opera di scienziati e tecnici che lavoravano per l’ARPA (Advanced Research Project Agency) del Ministero della Difesa degli Stati Uniti. Benché il progetto fosse finanziato dal bilancio militare, era chiaro fin dall’inizio che avrebbe avuto utilizzi civili. Si costruì un sistema di comunicazione che potesse sopravvivere all’eventuale non disponibilità di un nodo intermedio, nonché nei momenti di inefficienza, per temporaneo guasto o manutenzione. Si chiamava Arpa-net. All’inizio connetteva quattro grossi calcolatori.
Fin dall’inizio erano coinvolte alcune grosse strutture universitarie, che presto si impadronirono del sistema e lo misero al servizio della comunità scientifica. La National Science Foundation costituì una rete chiamata Nsf-net, che prese il sopravvento e alla fine degli anni ’80 incorporò Arpa-net. Erano già nate diverse reti, come UseNet, HepNet e BitNet; ma gli utenti delle varie reti volevano comunicare fra loro, e così si collegarono, usando il protocollo TCP/IP (Transmission Control Protocol - Internet Protocol) che fu definito nel 1978 e divenne lo standard condiviso nel 1983. Così era nata quella che prese il nome di inter-rete, cioè internet.
Un altro sistema fondamentale della rete era nato nel 1974: FTP (File Transfer Protocol – che usiamo ancora oggi ogni volta che preleviamo un file, che sia testo, software o altro, anche se spesso non ce ne accorgiamo).
Nello stesso periodo fu definito il sistema di gestione della posta (electronic mail, o e-mail come la chiamiamo abitualmente) e fu adottato per gli indirizzi il segno @ (at) che in Italia è familiarmente chiamato “la chioccioletta”. (Vedi il capitolo 48.
Il numero dei nodi cresceva continuamente. Nei primi anni il sistema collegava poche decine, poi poche centinaia di host (allora questo termine indicava una macchina specificamente progettata per collegarsi alla rete, ma con l’evoluzione delle tecnologie oggi ci possono essere molti host, cioè “indirizzi IP”, sullo stesso computer). Ai “server” connessi alla rete si collegano a loro volta i singoli computer, o le reti interne, degli utenti. Oggi l’internet collega 125 milioni di host e si stima che nel mondo ci siano più di 300 milioni di persone in grado di connettersi alla rete.
I primi collegamenti in Italia con la rete – che ancora non si chiamava internet – furono stabiliti dal Cnuce a Pisa nel 1982 (è tuttora a Pisa, presso il Cnr, la registration authority italiana). Nel mondo scientifico e universitario, all’inizio la presenza in rete fu dominata dalle facoltà di fisica; arrivarono più tardi i dipartimenti di scienza dell’informazione. Fino a cinque o sei anni fa, il sistema internet era usato quasi solo da alcuni grandi enti pubblici e da alcune facoltà universitarie. Erano pochi i “privati” che avevano un accesso in rete; la comunicazione fra le non molte persone collegate avveniva in buona parte con un altro sistema, l’echomail, gestito volontariamente dai BBS collegati a FidoNet o a altre reti che usano la cosiddetta “tecnologia fido”, diffusa nel mondo, e anche in Italia, dall’inizio degli anni ’80. Solo dal 1994 si è diffusa la disponibilità di accessi internet “per tutti”; e su questa base si è sovrapposta una nuova tecnologia, quella della World Wide Web.
La World Wide Web
Un’importante evoluzione nella rete è stata portata da una tecnologia che fu concepita da Tim Berners-Lee (al Cern di Ginevra) dieci anni fa, ma ebbe una larga diffusione solo nel 1994 (in Italia, un anno dopo). È nota come World Wide Web, o www, o the Web, la tela. Si basa sul protocollo HTTP (Hyper-Text Transfer Protocol) e sul linguaggio “ipertestuale” HTML (Hyper-Text Markup Language).
Tale è stato il successo di questa innovazione che oggi sembra essere “solo quello” il volto dell’internet. Molti nuovi utenti non conoscono la rete se non attraverso un browser con cui si accede ai “siti” web. Nulla di male, perché la tecnologia è solida, l’interfaccia è di facile uso, i browser si arricchiscono di nuove funzioni, e con un po’ di attenzione si scopre che è possibile accedere, anche per quella via, a tutti i sistemi e servizi connessi all’internet. Ma... ci sono due problemi.
Il primo è che se non si guarda oltre la “facciata” si può credere che “essere in rete” voglia dire solo andare in giro a guardare “siti web”, per vedere immagini, raccogliere informazioni, prelevare testi o software; mentre i valori più importanti della rete stanno nella comunicazione interattiva.
Il secondo è che il sovraccarico di immagini, che affligge buona parte dei “siti web”, produce “intasamenti” e rallentamenti nella rete. Di qui la snervante attesa di aspettare minuti prima che una sospirata pagina si completi sul nostro monitor. Conosco non poche persone che, avuta questa come prima e unica esperienza della rete, hanno rinunciato completamente a collegarsi.
Sono, naturalmente, solo “fasi di crescita”. Se dieci anni fa non sapevamo che ci sarebbe stata una cosa chiamata web, o se ne vedevano solo i primi accenni, tante cose ancora potranno cambiare. Quando la telefonia sarà tutta digitale, diventerà obsoleto il modulatore-demodulatore, o “modem”, che usiamo oggi. Forse anche le tecnologie su cui si basa l’internet un giorno saranno sostituite da qualcosa di diverso. Forse un giorno non ci saranno più tariffe interurbane, né intercontinentali, e con una “scheda dati” in un telefono tascabile in mezzo al Sahara potremo collegarci direttamente con Pechino. Anche le tariffe “urbane”, che rimangono troppo alte a causa di complesse (e non molto trasparenti) manovre, presto o tardi dovranno scendere (in Italia come in tutto il mondo) perché i costi “tendono a zero”.
Com’è spiegato in molte pagine di questo libro, l’essenza dell’internet non sta nelle tecnologie, ma nei rapporti fra le persone. Le possibilità di dialogo e si conoscenza aperte dalla rete sono molto più ampie e interessanti della semplice esplorazione di “siti web”.
La “cronologia”
contenuta in questa appendice
nell’edizione stampata del libro
si è molto estesa e arricchita
nella versione online
e perciò è stata collocata
in un documento separato
Si parla dell’internet come se fosse nata cinque o sei anni fa; ma le origini sono molto più lontane. Dalla storia degli eventi che hanno portato allo sviluppo della rete si rileva che l’internet è il punto di arrivo di diverse evoluzioni con radici estese nel tempo e definibili secondo almeno tre linee di sviluppo (non “parallele” o separate, spesso interconnesse, ma concettualmente distinte): elaborazione dei dati, gestione delle informazioni e sistemi di comunicazione. Mi sembra perciò interessante una sintetica cronologia del modo in cui si sono evolute queste risorse negli ultimi 300 anni.
Come funziona l’internet
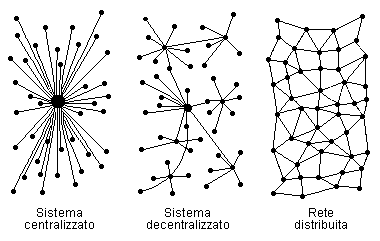
Questi tre diagrammi possono aiutarci a capire qual è la struttura dell’internet.
Questa rappresentazione grafica
è tratta dal libro di Katie Hafner e Matthew Lyon
Where Wizards Stay Up Late – The Origins of the Internet (1996).
In un sistema centralizzato, tutti i segnali passano da un unico punto.
In un sistema decentralizzato, un punto “vicino” può essere raggiunto attraverso un nodo periferico, ma un punto “remoto” può essere raggiunto solo passando dal centro (evidentemente la “distanza” non è determinata tanto dallo spazio fisico quanto dalla struttura del sistema). Questo sistema ha trovato applicazione in reti telematiche antecedenti alla diffusione dell’internet. Non solo nelle reti interne di imprese o altre grandi organizzazioni, ma anche, per esempio, nei collegamenti fra BBS, che dipendevano da una “gerarchia” di nodi assoggettata, a tutti i livelli, al controllo di chi stava più vicino al centro.
In una rete distribuita, l’informazione può percorrere molte strade diverse e scegliere in ogni momento il percorso più adatto per arrivare a destinazione, indipendentemente dalla distanza. Questo è il modello su cui è costruita la struttura dell’internet. La struttura del sistema è tale che la sede fisica del “sito” con cui ci si collega è irrilevante: in pratica non c’è alcuna differenza, né funzionale, né di costo, fra collegarsi con un “sito” (o un utente) a pochi metri di distanza o all’altro capo del pianeta. La distanza non è determinata dalla geografia, ma dal numero di passaggi (hop – letteralmente “salti”) che un messaggio deve fare per arrivare a destinazione.
Per esempio, se siamo connessi a un sistema con un forte collegamento transatlantico, un nodo negli Stati Uniti può essere più “vicino”, cioè più direttamente accessibile, di uno a pochi chilometri da noi ma con un sistema di connessione meno diretto.
In pratica, con un minuto o due di collegamento telefonico urbano possiamo spedire (e ricevere) decine di messaggi, da e per qualsiasi destinazione. Lo stesso messaggio può essere mandato contemporaneamente a una o a molte persone. La posta elettronica costa enormemente meno di qualsiasi altro sistema di comunicazione.
Il protocollo TCP/IP permette a tutti i sistemi connessi di interagire fra loro, senza una “gerarchia” rigida: cioè ogni “nodo” connesso può raggiungerne un altro scegliendo percorsi diversi secondo la situazione. Nel caso che un nesso intermedio non sia accessibile in quel momento, la comunicazione arriverà per un’altra via all’indirizzo stabilito (questa flessibilità rende il sistema più simile a una macchina analogica, come il cervello umano, che a un computer).
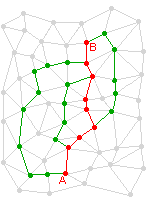
Mi perdonino i tecnici e le persone esperte per questa immagine grossolana e troppo semplificata. Ma il modo in cui un messaggio, o un’altra comunicazione, percorre la rete può essere rappresentato così.
Supponiamo che la strada più semplice (quindi teoricamente più veloce) da A a B sia quella rappresentata dalla linea rossa. Nel caso che qualcuno dei nodi lungo il percorso abbia qualche problema (come una momentanea inefficienza, un ritardo o un sovraccarico di traffico) il sistema cerca e trova una di tante possibili altre strade (qui simbolicamente rappresentate dalle linee verdi) che possono sembrare più complesse ma in pratica sono (in quel particolare momento) più efficienti e veloci. L’importante è che tutti i punti di smistamento (router) riconoscano il sistema di indirizzi e quindi sappiano come far proseguire il segnale verso la sua destinazione. Le distanze fra i nodi si misurano in millisecondi. La velocità del trasferimento non dipende dalla distanza fisica ma dalla qualità della connessione e dalla quantità dei dati che si vogliono trasferire (cioè dal “peso” del materiale mandato o richiesto).
Esiste una gerarchia internazionale di organizzazioni il cui compito è definire i domain internet, cioè il sistema su cui si basano gli indirizzi; ma non gestire le reti (che sono completamente autonome e indipendenti).
Gli scambi all’interno del sistema sono sostanzialmente gratuiti, perché basati sulla reciprocità: ogni “nodo” collegato dà e riceve servizio. Possono essere a pagamento le due estremità del sistema: il collegamento fra l’utente e il “nodo” di cui si serve (ISP – Internet Service Provider); e, al polo opposto, il servizio offerto da qualcuno sul “sito” con cui ci colleghiamo. Ma la rete, in quanto tale, è gratis.
(Le offerte di “accesso gratuito” che si sono diffuse nel 1999 non sono “gratis”; dobbiamo comunque pagare gli “scatti” telefonici e il provider guadagna con le sue entrate di “interconnessione”. All’altra estremità del sistema, invece, quasi tutti i “punti di arrivo” sono liberi e gratuiti; solo alcuni servizi particolari sono a pagamento).
La struttura fisica della rete è basata in larga misura sui cavi. Ma (come nella telefonia) si usano anche le comunicazioni “via etere”, compresi i “ponti radio” e i satelliti. La connessione dei singoli utenti rimane prevalentemente basata sui “fili del telefono”, ma naturalmente è possibile trasmettere dati anche con collegamenti wireless – per esempio con la telefonia cellulare.
La “congestione informativa”
e la crisi dei motori di ricercaCi sono miliardi di pagine nella world wide web. Il più potente dei “motori di ricerca” riesce a esplorarne un miliardo, ma ce ne sono molte di più; qualcuno pensa che siano 500 miliardi. Si stima che ogni giorno se ne aggiungano sette milioni. Una “pagina” può essere un testo di poche righe o di molte centinaia di parole. Alcuni analisti pensano che la quantità del materiale disponibile in rete stia superando il contenuto di tutti i libri pubblicati in tutto il mondo dalle origini della stampa ai nostri giorni.
Trovare tutto questo materiale e classificarne il contenuto è un’impresa enorme, che deve essere (in parte) delegata a sistemi automatici. Per quanto elaborati e raffinati possano essere quei sistemi, non hanno alcuna possibilità di essere “intelligenti” nel senso umano della parola. Sistemi “euristici” tentano di classificare i testi secondo la frequenza con cui compare una certa parola; ma questo non significa affatto che la graduatoria di rilevanza sia corretta. Per esempio un articolo su Scientific American del giugno 1999 spiegava che il libro di Tom Wolfe The Kandy-Kolored Tangerine-Flake Streamline Baby verrebbe classificato da uno di quei sistemi euristici come altamente rilevante per la parola “ernia”, perché all’inizio del testo è ripetuta dozzine di volte; mentre il libro parla di tutt’altro. D’altra parte, ci sono testi dedicati a un argomento che considerano una “parola-chiave” così ovvia da non citarla quasi mai. Le cose si complicano ancora di più quando intervengono interessi economici, per cui “motori” e repertori si fanno pagare per “favorire” alcune fonti a scapito di altre.
Il nuovo motore Google ha adottato un diverso criterio di “classificazione”, basato su un’analisi dei link: cioè su quali “fonti” sono più spesso indicate da altri siti in rete. È ancora presto per poter giudicare l’efficienza di questo sistema, ma i risultati sembrano interessanti.
Alle difficoltà che comunque esistono con qualsiasi testo si aggiungono talvolta le “astuzie” di chi introduce in una pagina (in modo palese o anche in forma “nascosta”, cioè in parti del linguaggio HTML non visibili in una normale lettura) ripetuti “segnali” intesi a farsi trovare, e a collocarsi in un punto alto della classifica, con parole-chiave intese ad aumentare il “traffico” e non a orientare correttamente la ricerca.
Fra i casi bizzarri c’è quello di un “furbo” che ha inserito il mio nome “nascosto” in alcuni documenti sul suo sito che non hanno alcun rapporto con me. Naturalmente lo potrei denunciare, ma non ho tempo da perdere... e sono quasi lusingato che qualcuno, sia pure con intenzioni “ingannevoli”, mi consideri un “richiamo”.
Il risultato è quello che tutti possiamo vedere. Se facciamo una ricerca molto “stretta”, cioè con una definizione precisa che contiene almeno una parola poco diffusa, troviamo un numero limitato di testi (ma probabilmente non tutti quelli che riguardano l’argomento che ci interessa). Se usiamo una parola semplice abbiamo più probabilità di trovare ciò che cerchiamo, ma il numero di alternative disponibili può essere esorbitante.
In italiano è più facile, perché c’è meno materiale? Direi di no. Prima di tutto, sono pochi gli argomenti per cui può essere sufficiente una ricerca in italiano; anche su temi “nostrani” c’è spesso materiale interessante in altre lingue. E poi, per quanto piccolo rispetto al totale, il volume del materiale in italiano è già sufficiente per mettere in crisi i motori di ricerca.
Prendiamo un motore e chiediamo “Dante Alighieri”. Trova 10.000 pagine; ma sono troppo poche... potrebbero esserci sfuggite molte cose. Infatti con la parola “Dante” da sola ne trova più di 200.000, con “Alighieri” 34.000. Con “inferno” 120.000, “Conte Ugolino” 60.000, “Beatrice” 200.000, “Pia de’ Tolomei” 80.000 (se usassimo “Pia” o “Tolomei” separatamente troveremmo un numero enorme di pagine che non riguardano quel personaggio). Con “Francesca da Rimini” ne troviamo 1.200, che benché poche rispetto alle altre chiavi di ricerca sono già un’esagerazione; e naturalmente non sono tutte, perché in molti testi è chiamata solo Francesca. Con “Paolo e Francesca” la lista scende a 200 pagine, che sono palesemente troppo poche. Ci sono le soluzioni cosiddette “booleane” che permettono di raffinare la ricerca; ma anche con quelle l’impresa è tutt’altro che facile. Per esempio se chiediamo i testi in cui le parole “Paolo” e “Francesca” sono vicine (near) ci vediamo offrire 200.000 pagine – di cui molte, ovviamente, nulla hanno a che fare con Dante. Naturalmente l’impresa è meno ardua se il territorio è più ristretto (per esempio se cerchiamo un commento su Dante di uno specifico autore). Ma in generale la ricerca in rete non è facile se non abbiamo un’idea abbastanza precisa di che cosa stiamo cercando – e di dov’è.
Inoltre, c’è il problema dei sinonimi. Con la chiave di ricerca “automobile” posso trovare una quantità enorme di informazioni, in inglese come in italiano. Ma oltre a doverci orientare in una massa già troppo abbondante ci mancherà molto materiale in cui si usa la parola “car” o “macchina” o “auto” e così via, moltiplicato per tanti sinonimi in tante lingue diverse. La parola “aircraft” è presente in un milione di pagine web; figuriamoci che cosa succede se aggiungiamo “airplane”, “aeroplano”, “aeromobile”, “velivolo” eccetera...
E, come abbiamo visto, le “graduatorie” non ci aiutano; è abbastanza improbabile che ciò che ci interessa sia fra le “prime 20” o “prime 100” pagine nell’elenco. Insomma, è difficile. E con il numero sempre crescente di pagine online il compito dei motori diventa sempre più arduo.
Si stanno studiando varie strade per rendere meno ingestibile la situazione. Per esempio un’analisi linguistica per migliorare la qualità delle analogie semantiche (cosa già difficile in inglese e piuttosto ardua se la si estende a una mescolanza di lingue diverse, compreso l’italiano). Ma gli analisti più seri di questi progetti ammettono che un’efficace gestione dei sinonimi e dei contesti è un’impresa molto difficile.
Benché ci sia qualche utile innovazione (come quella di Google) nessun automatismo può mai interpretare in modo preciso la graduatoria – anche perché ogni persona ha un concetto diverso di definizione delle priorità. Quando la situazione diventa difficile, una delle possibilità è provare con search engine diversi per vedere se (più o meno per caso) uno si comporta in un modo più adatto alle nostre esigenze.
Si stanno sviluppando concetti interessanti, come quello di mining community: cioè comunità di persone che condividono specifiche aree di interesse e lavorano insieme per trovare, produrre e organizzare le informazioni. Naturalmente ci sono già molte comunità di questo genere nella rete, ma può essere un’idea cercare di catalogarle, renderle più facilmente reperibili, aiutarle a conoscersi fra loro, eccetera.
Un’altra ipotesi è il concetto di hyperlink. Il modello è complesso e di non facile realizzazione. In sostanza implica la scelta di fonti “autorevoli” per diversi argomenti o settori della conoscenza, che possano funzionare come “nodi” o “stazioni di smistamento” nel mare magnum del materiale disponibile. In teoria l’idea può sembrare valida, ma in pratica ci sono grossi problemi. Il più preoccupante è che ci siano deformazioni e “centralizzazioni” arbitrarie. È molto probabile che su sistemi di questo tipo premano interessi economici e politici. E anche se così non fosse... è inevitabile che nella scelta dei “nodi autorevoli” intervengano pregiudizi culturali.
Insomma la situazione è complessa e in continua evoluzione; trovare soluzioni organizzate e sistematiche è molto difficile.
Il problema è ulteriormente aggravato dal fatto che molti “motori” e repertori online, disperatamente alla ricerca di profitti troppo ambiziosi, vendono le “graduatorie” e così compromettono sempre più gravemente la qualità del loro servizio. Vedi Quando l’arraffo è autolesionismo
Il problema della “congestione informativa” non è nato con la rete. Esiste, ed è oggetto di discussione e approfondimento, da molti anni. La disponibilità diretta di tanto materiale in rete lo ha solo reso più evidente. Ma oggi, con la rete, ci aspettiamo che in qualche modo il problema sia più facilmente risolvibile. E restiamo delusi quando “tocchiamo con mano” quanto sia difficile orientarsi nell’enorme quantità del materiale disponibile.
Quali saranno le soluzioni? È difficile prevederlo. Ma mi sembra necessario che siano più di una. Già oggi esistono, nel mondo, migliaia di “motori di ricerca” e il numero tende ad aumentare. Lo sviluppo più desiderabile per il futuro è una crescente specializzazione, così che ciascuno possa scegliere i nodi e le fonti più affini alle sue esigenze. Ma nulla, mai, potrà sostituire la curiosità personale e la ricerca di strade meno ovvie; nessuna soluzione tecnica, per quanto raffinata, potrà sostituire il filo sottile ma forte dei rapporti umani e la capacità individuale di scoprire, con ingegno, fantasia e un po’ di fortuna, quei percorsi meno facili ed evidenti che sono spesso i più utili.
Per evitare un eccessivo ingombro
l’analisi storica che si trovava
alla fine di questa appendice
(molto ampliata rispetto al testo nel libro)
ora si trova om un documento a parte
cronologia
Indice dei capitoli online
Ritorno alla pagina
di presentazione del libro