Capitolo 9. Introduzione alle reti TCP/IP
- Sommario
- 9.1. Reti TCP/IP
- Bibliography
9.1. Reti TCP/IP
L'autore di questo capitolo (Introduzione alle reti TCP/IP) è Hubert Feyrer <hubert@feyrer.de>.
9.1.1. Introduzione
Il presente capitolo della guida è dedicato alle reti delle quali spiega gli elementi fondamentali per i lettori che non hanno grande familiarità con l'argomento. Il capitolo seguente, invece, contiene un'introduzione pratica alla configurazione di rete di NetBSD; che desidera configurare rapidamente la rete può iniziare con il prossimo capitolo e poi tornare con calma alla lettura del capitolo presente.
Da parte del lettore è richiesta la conoscenza di elementi di base dell'amministrazione del sistema: come diventare "root", come editare i file, come cambiare i permessi ai file, come fermare un processo, ecc. Vedere per esempio [AeleenFrisch] per approfondire questi argomenti. Altre a ciò, è necessario saper usare alcuni programmi di utilità quali telnet, ftp, ... Tali programmi non verranno qui descritti e, pertanto, per ulteriori informazioni si rimanda alle relative pagine di manuale, alla bibliografia e agli altri capitoli di questa guida.
Questa introduzione alle reti TCP/IP non ha pretesa di completezza: chi desidera approfondire gli argomenti trattati per avere un quadro più completo può fare riferimento a [CraigHunt]. Questo libro, oltre a descrivere gli elementi di base, spiega tutti i concetti e i dettagli necessari alla configurazione di tutti i servizi: un ottimo libro.
9.1.2. Protocolli di rete supportati
NetBSD supporta vari protocolli di rete, la maggior parte dei quali ereditati dal suo predecessore, 4.4BSD, e successivamente estesi e migliorati. Il primo protocollo implementato è quello oggi più importante, il Transmission Control Protocol/Internet Protocol (TCP/IP) del DARPA. Altri protocolli disponibili su NetBSD sono Xerox Network System (XNS), implementato all'UCB per collegare in rete macchine isolate, AppleTalk di Apple, ISO, CCITT X.25 e ARGO TP. Questi ultimi protocolli sono oggi usati solo da alcune speciali applicazioni.
Oggi TCP/IP è il protocollo più diffuso tra quelli menzionati al paragrafo precedente. Oltre a essere implementato da ogni sistema operativo e su ogni tipo di hardware, è anche il protocollo più usato in ambienti eterogenei. Pertanto, TCP/IP è la scelta più giusta per collegare il proprio computer a altre macchine a casa o alla rete aziendale o universitaria.
La versione corrente del protocollo TCP/IP è la 4 (IPv4); la versione 6 (IPv6) è in corso di sviluppo e il codice IPv6 del progetto KAME è stato integrato nelle release di NetBSD già a partire dalla 1.5.
Vi sono anche dei protocolli che non sono supportati da NetBSD, quali DECNET, IPX/SPX di Novell e NetBIOS di Microsoft. Questi protocolli, a differenza dei precedenti, sono proprietari, e non sono quindi definiti da alcuna RFC pubblica come gli altri standard aperti.
9.1.3. Interfacce supportate
Il protocollo TCP/IP può essere utilizzato su un'ampia gamma di interfacce. Tra quelle supportate da NetBSD ricordiamo Ethernet (10/100/1000MBd), linea seriale Arcnet, ATM, Fiber Channel, USB, HIPPI, FireWire (IEEE 1394), Token Ring, linee seriali e altre ancora.
9.1.3.1. Linee seriali
Vi sono varie ragioni che consigliano l'uso di TCP/IP su linea seriale.
se un host remoto è raggiungibile solo per telefono, lo si può contattare via modem.
praticamente tutti i computer dispongono di un'uscita seriale, e il cavo necessario è molto economico.
Lo svantaggio dei collegamenti via seriale è che sono più lenti degli altri metodi. NetBSD può utilizzare al massimo 115300 bit/s, il che rende il collegamento molto più lento rispetto ai 10 Mbit/s di Ethernet o ai 4 Mbit/s di Arcnet.
Per collegare un host con NetBSD a un altro host via seriale, eventualmente anche su linea telefonica, si possono usare due metodi:
Serial Line IP (SLIP)
Point to Point Protocol (PPP)
La scelta dipende dal tipo di collegamento che si vuole effettuare. Per un collegamento telefonico utilizzando il modem conviene sfruttare PPP, che offre l'opzione di auto negoziare gli indirizzi IP e l'instradamento, cose complicate da impostare a mano. Invece, per collegarsi direttamente a un'altra macchina, per esempio con un cavo null-modem o una linea dedicata, il protocollo SLIP è più semplice da configurare con indirizzi e instradamento fissi ed è supportato praticamente da tutti i sistemi operativi.
PPP su una linea diretta è più difficile da configurare rispetto a SLIP a causa dell'handshake iniziale, che su SLIP non è presente. Ciò significa che con SLIP si inizia il collegamento da un lato e l'altro lato può inviare il primo pacchetto non appena è pronto.
[RFC1331] e [RFC1332] descrivono i protocolli PPP e TCP/IP su PPP. SLIP è descritto in [RFC1055].
9.1.3.2. Ethernet
Ethernet è l'interfaccia più utilizzata nell'ambito delle reti locali (LAN, Local Area Network) di macchine interconnesse in un'area limitata, quale può essere un ufficio, un'azienda o un'università. Ethernet si basa su un bus al quale possono connettersi più macchine e la comunicazione avviene sempre tra due nodi alla volta. Quando più coppie di nodi cercano di comunicare contemporaneamente si verifica un conflitto e le coppie cercheranno di riprovare la comunicazione al termine di un timeout. Il termine tecnico utilizzato per questa procedura è CSMA/CD (Carrier Sense w/ Multiple Access and Collision Detection.)
Inizialmente, l'hardware Ethernet consisteva in uno spesso cavo (giallo) che veniva collegato alle macchine usando speciali connettori che attraversavano la schermatura esterna del cavo stesso. Successivamente è arrivato il tipo 10base5, che usava connettori di tipo BNC da inserire in speciali connettori a T sulle macchine, con terminatori alle estremità della linea. Oggi il bus ethernet è contenuto all'interno degli switch e degli hub, e i cavi sono del tipo twisted pair e danno il nome a questo tipo di interfaccia: 10baseT per le reti a 10 Mbit/s e 100baseT per quelle a 100 Mbit/s. Nelle reti configurate con switch, si distinguono i due casi in cui la comunicazione tra nodo e switch avviene in modo full-duplex o half-duplex.
9.1.4. Il formato degli indirizzi TCP/IP
La corrente implementazione del protocollo TCP/IP (IPv4) usa identificativi di 4 byte (32 bit) (detti anche indirizzi IP) per indirizzare gli host.
Questi indirizzi IP sono unici a livello mondiale. Per raggiungere questo scopo, la loro amministrazione è delegata a un organismo centrale, InterNIC, che assegna gruppi di indirizzi direttamente ai siti che vogliono collegarsia Internet o ai provider, che li ridistribuiscono ai propri clienti.
Tutte le università e le ditte collegate a Internet hanno almeno uno di questi indirizzi, generalmente non assegnato direttamente da InterNIC ma ottenuto da un Internet Service Provider (ISP.)
Per configurare la rete privata di casa è sufficiente "costruirsi" i propri indirizzi IP privati come spiegato nel seguito. Per collegare le proprie macchine a Internet, però, è necessario ottenere un "vero" indirizzo IP dal proprio amministratore di rete o dal provider.
Per la scrittura degli indirizzi IP viene usata prevalentemente una notazione detta dotted quad (quadrupla puntata), nella quale i quattro byte dell'indirizzo vengono scritti uno alla volta (a partire dal più significativo) separandoli con un punto. Per esempio 132.199.15.99 è un indirizzo valido. Un indirizzo può anche essere scritto utilizzando una parola da 32 bit in esadecimale, per esempio: 0x84c70f63. Questo formato non è così intuitivo come il precedente, ma a volte può rivelarsi utile come si vedrà nelle sezioni seguenti.
Assegnare una rete a un host significa semplicemente impostare a determinati valori alcuni dei 32 bit dell'indirizzo dell'host. Questi bit, usati per identificare la rete, vengono detti "bit di rete". I restanti bit servono per identificare l'host all'interno della rete, e vengono pertanto detti "bit dell'host".
Nell'esempio precedente, l'indirizzo di rete è 132.199.0.0 (in un indirizzo di rete i bit dell'host sono messi a zero) mentre l'indirizzo dell'host nella rete è 15.99.
Come si fa a sapere che l'indirizzo dell'host occupa 16 bit? Semplice, viene indicato dal provider da cui si ottiene l'indirizzo stesso. Nell'instradamento senza classi tra domini (Classless Inter-Domain Routing, CIDR) utilizzato oggi, il numero di bit riservati all'host va da 2 a 16 e il numero di bit riservato alla rete viene scritto dopo l'indirizzo IP, separato da un "/". Per esempio, 132.199.0.0/16 indica che la rete in questione ha 16 bit. Quando ci si riferisce alla "dimensione" di una rete lo si fa solitamente semplicemente con "/16", "/24", ecc.
Prima dell'avvento del CIDR le reti venivano divise in quattro classi. Ogni classe iniziava con una ben precisa sequenza di bit che la identificava. In dettaglio:
La Classe A inizia con "0" come bit più significativo. I successivi 7 bit di un indirizzo di classe A identificano la rete e i restanti 24 bit vengono usati per indirizzare l'host. Pertanto, in una rete di classe A ci possono essere 224 host. Non è facile, tuttavia, per una ditta o per un'università ottenere un intero indirizzo di classe A.
La notazione CIDR per una rete di classe A con i suoi 8 bit di rete è "/8".
La Classe B inizia con "10" come bit più significativi. I successivi 14 bit identificano la rete e i restanti 16 bit servono per indirizzare gli host (oltre 65000). Gli indirizzi di classe B, una volta molto comuni per ditte e università, sono oggi difficili da ottenere a causa dell'attuale scarsità di indirizzi IPv4 disponibili.
La notazione CIDR per una rete di classe A con i suoi 16 bit di rete è "/16".
Ritornando all'esempio precedente, si può vedere che l'host 132.199.15.99 (o l'equivalente esadecimale 0x84c70f63, che qui è più comodo) si trova in una rete di classe B, poiché 0x84 = 1000... (in binario).
Pertanto, l'indirizzo 132.199.15.99 può essere diviso nella parte di rete che è 132.199.0.0 e nella parte host che è 15.99.
La Classe C viene identificata dai bit più significativi (detti anche MSB, Most Significant Bits) uguali a "110", consentendo solo 256 host su ognuna delle 221 possibili reti di classe C (in realtà, come si verdrà dopo, il numero di host possibili è 254). Gli indirizzi di classe C si trovano solitamente in piccole ditte.
La notazione CIDR per una rete di classe C con i suoi 24 bit di rete è "/24".
Esiste anche un'ulteriore serie di indirizzi, che iniziano con "111", che vengono usati per altri scopi (per esempio multicast) e non che interessano in questa sede.
Si noti che i bit utilizzati per identificare la rete fanno comunque parte dell'indirizzo di rete stesso.
Quando si separa la parte di rete da quella di host è comodo utilizzare la cosidetta netmask (maschera di rete). Si tratta di una valore da usare come "maschera" in cui tutti i bit di rete sono messi a "1" e tutti i bit di host sono a "0". Mettendo insieme con un AND logico l'indirizzo con la netmask si ottiene l'indirizzo della rete.
Rifacendoci all'esempio precedente, 255.255.0.0 è una possibile netmask di 132.199.15.99. Quando si applica la netmask all'indirizzo, rimane la parte di rete 132.199.0.0.
Per gli indirizzi in notazione CIDR, il numero indicato di bit di rete specifica anche quali dei bit più significativi devono essere messi a "1" per ottenere la netmask della rete corrispondente. Per gli indirizzi di rete di classe A/B/C esiste una netmask di default:
Class A (/8): netmask di default: 255.0.0.0, primo byte dell'indirizzo: 1-127
Class B (/16): netmask di default: 255.255.0.0, primo byte dell'indirizzo: 128-191
Class C (/24): netmask di default: 255.255.255.0, primo byte dell'indirizzo: 192-223
Un tipo particolare di indirizzo che è bene conoscere è l'"indirizzo di broadcast". I messaggi inviati a questo indirizzo vengono ricevuti da tutti gli host della rete corrispondente. L'indirizzo di broadcast è caratterizzato dal fatto di avere tutti i bit di host messi a "1".
Per esempio, dato l'indirizzo 132.199.15.99 con la maschera di rete (netmask) 255.255.0.0, l'indirizzo di broadcast è 132.199.255.255.
A questo punto ci si può chiedere: si può utilizzare un indirizzo di host con tutti i bit a "0" o a "1"? La risposta è no, perché il primo è l'indirizzo della rete e il secondo l'indirizzo di broadcast, e questi due indirizzi devono sempre essere presenti. Adesso si può capire perché una rete di classe B può contenere al massimo 216-2 host e una rete di classe C ne può contenere 28-2 = 254.
Oltre ai vari tipi di indirizzi già citati, ce n'è un altro che è speciale; è l'indirizzo IP 127.0.0.1 che si riferisce sempre all'host locale (localhost.) Ciò significa che quando si "parla" con 127.0.0.1 si comunica in realtà con se stessi, senza dare luogo a alcuna attività di rete, il che può essere utile per utilizzare servizi installati sulla propria macchina o per fare simulazioni e test quando non ci sono altri host sulla rete.
Per riassumere quanto discusso finora:
- Indirizzo IP
indirizzo di 32 bit, comprendente la parte di rete e la parte di host.
- Indirizzo di rete
indirizzo IP con tutti i bit di host messi a "0".
- Netmask (maschera di rete)
maschera di 32 bit in cui i bit che si riferiscono alla rete sono messi a "1" mentre quelli che si riferiscono all'host sono a "0".
- Indirizzo di broadcast
indirizzo IP con tutti i bit di host messi a "1".
- Localhost
l'indirizzo IP dell'host locale è sempre 127.0.0.1.
9.1.5. Subnetting e routing
La precedente sezione ha descritto in dettaglio le maschere di rete e gli indirizzi di host e di rete. Il discorso sulle reti, però, è tutt'altro che concluso.
Consideriamo la situazione di una tipica università, con un indirizzo di classe B (/16), che le consente di avere fino a 216 ~= 65534 host sulla rete. Anche se sarebbe comodo pensare di avere tutti questi host sulla stessa rete, ciò non si può realizzare a causa delle limitazioni fisiche dell'hardware in uso oggi.
Per esempio, la massima lunghezza di un cavo Ethernet thinwire è di 185 metri. Anche mettendo dei ripetitori che amplificano il segnale tra le postazioni, questo non basta per raggiungere tutte le postazioni in cui si trovano le macchine. Inoltre, il massimo numero di host su un cavo Ethernet thinwire è di 1024 e, avvicinandosi a questo limite, si ha una perdita di prestazioni.
Pertanto ci troviamo in una situazione in cui si abbiamo un indirizzo che ci consentirebbe di avere 60000 host ma siamo limitati dai collegamenti, che ci permettono di raggiungere un numero molto inferiore di postazioni.
Naturalmente la soluzione c'è, e consiste nel suddividere la "rete" di classe B in reti più piccole, solitamente dette sottoreti. Queste sottoreti possono ospitare, per esempio, fino a 254 host l'una (cioè abbiamo suddiviso la grande rete di classe B in più sottoreti di classe C).
Per ottenere questo risultato, bisogna modificare la maschera di rete per avere più bit di rete e meno bit di host. Questo generalmente si fa lavorando sui byte della maschera (anche se è possibile scendere a livello dei singoli bit). Quindi la cosa più semplice è trasformare la maschera di rete da 255.255.0.0 (classe B) a 255.255.255.0 (classe C).
Usando la notazione CIDR, si scrive ora "/24" anziché il precedente "/16" per indicare che vengono usati 24 bit dell'indirizzo per identificare la rete e la sottorete, invece dei 16 usati prima.
Questa modifica ci consente di avere un byte di rete in più da assegnare a ognuna delle reti fisiche. Tutti i 254 host di ogni rete possono comunicare tra loro direttamente e si possono creare 256 reti di questo tipo (classe C). questa nuova configurazione dovrebbe essere adeguata alle esigenze della nostra ipotetica università.
Per chiarire meglio il concetto, continuiamo con l'esempio precedente. Supponiamo che il nostro host sia 132.199.15.99, che si chiami dusk e che abbia la netmask 255.255.255.0, il che significa che si trova sulla sottorete 132.199.15.0/24. Naturalmente vi sono anche altri host, come si vede dalla Figura 9-1.
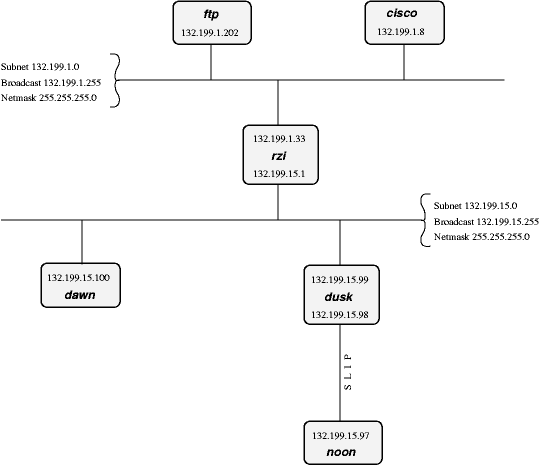
Nella rete dell'esempio, dusk può parlare direttamente con dawn, poiché entrambi si trovano sulla stessa sottorete. Ci sono anche altri host sulla sottorete 132.199.15.0/24, ma per ora non li consideriamo.
Cosa succede se dusk vuole parlare con un host che si trova su un'altra sottorete? In questo caso il traffico uno o più gateway (router), attaccati alle due sottoreti. Per questo motivo un gateway ha sempre due indirizzi diversi, uno per ognuna delle sottoreti a cui è collegato. Dal punto di vista funzionale il router è del tutto trasparente per gli host, cioè non è necessario conoscerne l'indirizzo per raggiungere gli host che stanno dall'"altra parte". È sufficiente indirizzare direttamente gli host e i pacchetti giungeranno a destinazione correttamente.
Per esempio, supponiamo che dusk voglia scaricare dei file dal server FTP locale. Poiché dusk non può raggiungere ftp direttamente (perché si trova su una sottorete diversa) tutti i suoi pacchetti saranno inoltrati al suo "router di default" rzi (132.199.15.1), che sa dove deve inviarli perché giungano a destinazione.
Dusk conosce l'indirizzo del router di default della sua rete (rzi, 132.199.15.1), e inoltra a lui tutti i pacchetti che non sono destinati alla stessa sottorete, cioè, in questo caso, tutti i pacchetti IP che hanno il terzo byte dell'indirizzo diverso da 15.
Il router di default invia i pacchetti all'host appropriato, visto che si trova anche sulla sottorete del server FTP.
In questo esempio tutti i pacchetti vengono inviati alla rete 132.199.1.0/24, semplicemente perché si tratta della backbone della rete, la parte più importante della rete, che trasporta tutto il traffico di passaggio tra varie sottoreti. Quasi tutte le sottoreti oltre a 132.199.15.0/24 sono collegate alla backbone in modo simile.
Che cosa succede se colleghiamo un'altra sottorete a 132.199.15.0/24 invece di 132.199.1.0/24? Probabailmente qualcosa di simile alla situazione descritta nella Figura 9-2.
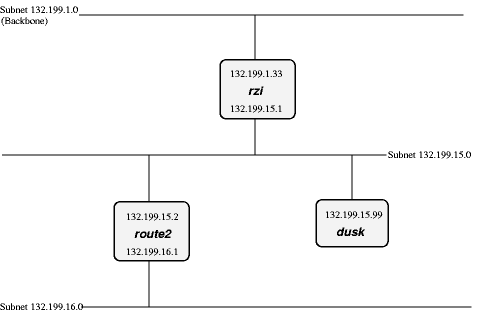
Adesso, per raggiungere un host che si trova sulla sottorete 132.199.16.0/24 da dusk, non si possono inoltrare i pacchetti a rzi, ma bisogna inviarli diretamemente a route2 (132.199.15.2). Dusk deve sapere che deve inoltrare questi pacchetti a route2 e inviare tutti gli altri a rzi.
Quando si configura dusk, gli si indica di inviare tutti i pacchetti per la sottorete 132.199.16.0/24 a route2, e tutti gli altri a rzi. Invece di esplicitare questo default con 132.199.1.0/24, 132.199.2.0/24, ecc., si può usare il valore 0.0.0.0 per impostare la route di default.
Ritornando alla Figura 9-1, si verifica un problema simile quando dawn vuole inviare a noon, che è collegato a dusk via linea seriale. Dall'esame del suo indirizzo IP, noon sembrerebbe essere attaccato alla rete 132.199.15.0, ma non lo è realmente. Invece, dusk viene usato come gateway e dawn deve inviare i suoi pacchetti a dusk, che li inoltrerà a sua volta a noon. Il sistema grazie al quale dusk viene forzato a accettare pacchetti che non sono destinati a lui ma a un altro host (noon) viene definito "proxy arp".
Lo stesso discorso vale quando un host di un'altra sottorete vuole inviare a noon. Dovrà inviare i suoi pacchetti a dusk (eventualmente inoltrati da rzi).
9.1.6. Concetti di Name Service
Nelle sezioni precedenti, nel fare riferimento agli host abbiamo spesso utilizzato il loro indirizzo IP. questo era necessario per spiegare le differenze fra i vari tipi di indirizzi. In generale, tuttavia, quando si parla di host è più comodo utilizzare il loro "nome", come abbiamo fatto nella sezione sul routing.
Alla maggior parte delle applicazioni non importa se gli host sono specificati usando il nome o l'indirizzo IP. Tuttavia, internamente esse usano gli indirizzi IP, ed esistono vari metodi che possono utilizzare per convertire i nomi degli host in indirizzi IP. In questa sezione verranno introdotti i concetti che stanno alla base di ognuno di questi metodi. Successivamente verrà spiegato come effettuarne la configurazione.
La conversione dei nomi degli host (e dei domini) in indirizzi IP, viene effettuata da un modulo software detto resolver. Non si tratta di un servizio aggiuntivo ma di una serie di funzioni di libreria che vengono collegate a ogni applicazione che usa funzioni di rete. Il resolver cerca di "risolvere" (da cui il nome) i nomi degli host in indirizzi IP. Si veda [RFC1034] e [RFC1035] per ulteriori dettagli sul resolver.
I nomi degli host hanno generlamente una lunghezza massima di 10 caratteri e possono contenere lettere, numeri e trattini ("-"). Maiuscole e minuscole sono considerate equivalenti.
Proprio come per le reti e le sottoreti, è possibile (anzi desiderabile) raggruppare gli host in domini e sottodomini. Quando si ottiene un indirizzo di rete dal provider, generalmente si ottiene anche un nome di dominio. Come per le sottoreti, è lasciato all'utente il compito di creare sottodomini. I sottodomini non sono in relazione diretta con le sottoreti; per esempio, un dominio può contenere host collegati a diverse sottoreti.
Figura 9-1 mostra le sottoreti 132.199.1.0/24 e 132.199.15.0/24 (e le altre) che fanno parte del sottodominio rz.uni-regensburg.de. Il dominio che l'università di Regensburg ha ottenuto dal suo provider IP è "uni-regensburg.de" (".de" indica la Germania, Deutschland), il sottodominio "rz" indica il Rechenzentrum (Centro di Calcolo).
I nomi degli host, dei sottodomini e dei domini sono separati da punti ("."). È anche possibile, sebbene non comune, usare più di un livello di sottodominio; per esempio: fox_in.socs.uts.edu.au.
Un nome di host che comprende il (sotto)dominio viene detto nome di dominio completamente qualificato (FQDN, Fully Qualified Domain Name). Per esempio, l'indirizzo IP 132.199.15.99 appartiene all'host il cui FQDN è dusk.rz.uni-regensburg.de.
In precedenza è stato detto che l'indirizzo IP 127.0.0.1 appartiene sempre all'host locale, qualunque sia il "vero" indirizzo IP dell'host stesso. Pertanto, 127.0.0.1 è sempre mappato al nome localhost.
I tre metodi diversi di tradurre un nome di host in un indirizzo IP sono: /etc/hosts, il Domain Name Service (DNS) e il Network Information Service (NIS).
9.1.6.1. /etc/hosts
Il primo e il più semplice dei tre metodi per tradurre da nome host a indirizzo IP consiste nell'usare una tabella che mette in corrispondenza i nomi e i relativi indirizzi. Questa tabella si trova nel file /etc/hosts e ha il formato seguente:
indirizzo IP nome host [alias [...]]
Le linee che iniziano con un cancelletto ("#") sono considerate commenti e vengono ignorate. Le altre linee contengono un indirizzo IP e il/i corrispondenti nomi di host.
Non è possibile che un nome di host corrisponda a più indirizzi IP. rzi, per esempio, ha due nomi diversi per i suoi due indirizzi: rzi e rzia.
Può essere comodo dare più nomi (alias) a un host; ciò consente di specificare un nome alternativo per l'host in relazione a un particolare servizio, come viene comunemente fatto, per esempio, per i server FTP. Il primo nome (quello più a sinistra) è solitamente il nome reale (canonico) dell'host.
Può anche essere utile usare il nome completo (FQDN) dell'host come nome canonico, e il suo hostname (senza dominio) come alias.
Importante: ci deve sempre essere una voce per il mapping di localhost su 127.0.0.1!
9.1.6.2. Il Domain Name Service (DNS)
L'uso di /etc/hosts comporta un problema, specialmente nelle reti di grandi dimensioni: quando si aggiunge un host o si cambia l'indirizzo di un host, tutti i file /etc/hosts di tutte le macchine devono essere aggiornati. Non solo questo comporta una perdita di tempo, ma è anche una possibile causa di errori e inconsistenze che inevitabilmente porteranno a dei problemi.
Un'altro sistema è di mantenere una sola tabella di nomi di host (database) per l'intera rete e di fare in modo che tutti i client interroghino quel "nameserver". Gli aggiornamenti saranno effettuati solo sul name server.
Questa è l'idea di base su cui si fonda il Domain Name Service (DNS).
Solitamente c'è un name server per ogni dominio (da cui il nome Domain Name Service) e ogni host nel dominio sa a quale dominio appartiene e quale name server deve interrogare per il proprio dominio.
Quando il DNS riceve un'interrogazione per un host che non si trova nel suo dominio, la inoltra al DNS del dominio corrispondente oppure a un DNS che sa a quale DNS chiedere l'informazione. Quest'ultimo inoltra l'interrogazione a un DNS di livello superiore, e così via. Questo processo non va avanti all'infinito: vi sono vari server "root" che posseggono le informazioni di tutti i domini.
Vedere Capitolo 11 per ulteriori dettagli sul DNS.
9.1.6.3. Il Network Information Service (NIS/YP)
Le Yellow Pages (YP) sono state inventate dalla Sun Microsystems. Il nome è stato poi cambiato in Network Information Service (NIS) perchè YP era già un marchio della British Telecom.
Nei sistemi Unix sono solitamente presenti un gran numero di file di configurazione ed è pertanto spesso desiderabile di limitare la manutenzione di questi file a un paio di host. Gli host vengono quindi raggruppati in domini NIS (che non hanno niente a che vedere con i domini DNS) e fanno solitamente parte di un cluster di workstation.
Alcuni dei file di configurazione condivisi tra questi host sono /etc/passwd, /etc/group e /etc/hosts.
È quindi possibile "abusare" del NIS per ottenere un'unica traduzione da nome a indirizzo su tutti gli host di un dominio NIS.
C'è solo uno svantaggio che impedisce a NIS di essere effettivamente utilizzato per questo tipo di traduzione: a differenza del DNS, NIS non fornisce alcun metodo per risolvere i nomi degli host che non fanno parte della tabella degli host. Non esistono host di livello superiore che il server NIS può interrogare e, pertanto, la traduzione è destinata a fallire. NIS+, sempre della Sun, affronta questo problema, ma poiché NIS+ è disponibile solo sui sistemi Solaris non ci è di grande aiuto.
Quanto detto non significa che NIS non sia un metodo eccellente per gestire, per esempio, le informazioni sugli utenti (/etc/passwd, ...) in cluster di workstation; semplicemente nonè molto utile per risolvere i nomi degli host.
9.1.6.4. Altri metodi
I metodi fin qui descritti per la risoluzione dei nomi degli host in indirizzi IP, sono quelli oggi di uso più comune, ma non sono gli unici. In linea di massima si può utilizzare un database qualsiasi, ma non vi sono implementazioni di questo tipo in NetBSD.
NIS+, come già detto, cerca di rimediare alla mancanza di gerarchia nelle strutture dati NIS. Le tabelle possono essere impostate in modo che se un'interrogazione non può essere soddisfatta dal server di un dominio, ci può essere un altro dominio di livello superiore in grado di dare una risposta. Per esempio, si può definire un dominio che elenca tutti gli host (utenti, gruppi, ecc.) appartenenti a tutta una ditta, un altro che definisce gli stessi dati per ogni divisione, e così via. NIS+ non è correntemente molto usato, persino la stessa Sun ha ripreso a fornire NIS di default.
In passato, lo standard X.500 era stato progettato per gestire sia database semplici, come /etc/hosts, sia strutture gerarchiche complesse come, per esempio, l'attuale DNS. X.500 non ha mai avuto molto successo, in parte perché cercava di fare troppe cose contemporaneamente. Una versione ridotta, chiamata LDAP (Lightweight Directory Access Protocol) è oggi disponibile e la sua popolarità sta crescendo negli ultimi anni per gestire i dati degli utenti (ma anche degli host) in organizzazioni di piccole e medie dimensioni.
9.1.7. IPv6, il protocollo Internet di nuova generazione
9.1.7.1. Il futuro di Internet
A giudizio degli esperti, Internet nella sua forma attuale si troverà a affrontare un problema serio nel giro di pochi anni. A causa della sua rapida crescita e delle limitazioni nella sua progettazione, si arriverà a un punto in cui non saranno più disponibili indirizzi per connettere nuovi host. In quel momento, non si potranno più aggiungere nuovi server web, gli utenti non potranno ottenere account dagli ISP, non si potranno collegare nuove macchine in rete per accedere al web o partecipare ai giochi online - in breve, un problema molto serio.
Sono stati pensati vari approcci per risolvere questo problema. Un metodo molto diffuso consiste nel non assegnare un indirizzo valido univoco a ogni macchina collegata, ma di assegnare indirizzi "privati" e di "nascondere" più macchine dietro a un unico indirizzo ufficiale globale. Questo metodo, che si chiama Network Address Translation (NAT, noto anche come IP Masquerading) presenta dei problemi, perché le macchine nascoste dietro l'unico indirizzo globale non possono essere indirizzate direttamente e, pertanto, non è possibile aprire connessioni con loro, come richiesto, per esempio, dai giochi online, dalle reti peer-to-peer, ecc. Per una discussione sugli svantaggi di NAT, vedere [RFC3027].
Un approccio diverso al problema della scarsità di indirizzi internet è di abbandonare il vecchio protocollo Internet e le sue limitate capacità di indirizzamento in favore di un nuovo protocollo che non soffre di queste limitazioni. Il protocollo, o meglio l'insieme di protocolli, usato dalle macchine connesse a formare l'attuale Internet è noto come suite TCP/IP (Transmission Control Protocol, Internet Protocol), e la versione 4, quella in uso adesso, ha tutti i problemi appena descritti. Per poter passare a una nuova versione del protocollo che risolve questi problemi bisogna ovviamente che tale versione "migliore" esista. E infatti, la versione 6 dell'Internet Protocol (IPv6) esiste, e risponde a tutte le possibili future esigenze di spazio di indirizzamento, affrontando anche altri problemi quali la segretezza, la crittografia e un miglior supporto al mobile computing.
Questa sezione introduce il protocollo IPv6; per una buona comprensione si richiede una conoscenza di base del funzionamento del protocollo IPv4. Vengono descritti i cambiamenti nel formato dell'indirizzo e nella risoluzione dei nomi. Sfruttando queste informazioni, la Sezione 10.2.4 mostrerà come utilizzare IPv6 anche se non viene offerto dall'ISP utilizzando un meccanismo di transizione semplice ma efficace denominame 6to4. Lo scopo finale è di ritrovarsi online con IPv6, mostrando una configurazione di esempio per NetBSD.
9.1.7.2. Perché passare a IPv6?
Quando si consiglia a qualcuno di passare da IPv4 a IPv6, la prima domanda che ci si sente rivolgere è "perché"? Vi sono varie buone ragioni:
Spazio di indirizzamento più grande.
Supporto al "mobile computing".
Gestione integrata della sicurezza.
9.1.7.2.1. Maggiore spazio di indirizzamento
L'ampliamento dello spazio di indirizzamento offerto è il primo dei vantaggi offerti da IPv6 rispetto a IPv4. L'attuale architettura di Internet è basata su indirizzi di 32 bit, mentre la nuova versione dispone di indirizzi di 128 bit. Grazie a questo ampliamento, non sarà più necessario utilizzare soluzioni quali NAT e ciò porterà a una completa e illimitata connettività per tutte le attuali macchine basatae su IP nonché per i nuovi dispositivi mobili quali PDA e telefoni cellulari, che potranno disporre del completo accesso IP grazie a GPRS e UMTS.
9.1.7.2.2. Mobilità
Quando si parla di dispositivi mobili e IP, un punto importante da tenere presente è che è necessario un protocollo speciale per supportare la mobilità; l'implementazione di questo protocollo, detto Mobile IP, è uno dei requisiti di ogni stack IPv6. Pertanto, quando si attiva IPv6 si ottiene il supporto per il roaming tra reti diverse, con l'aggiornamento completo quando si lascia una rete e ci si trasferisce su un'altra. Il supporto al roaming è possibile anche con IPv4, ma bisogna risolvere alcuni problemi prima di ottenere un sistema funzionante. Con IPv6 non è necessario alcun accorgimento particolare, poiché il supporto alla mobilità è uno dei requisiti di progetto di IPv6. Vedere [RFC3024] per ulteriori informazioni sui problemi da risolvere per supportare il "mobile IP" su IPv4.
9.1.7.2.3. Sicurezza
Oltre al supporto per la mobilità, la sicurezza era uno dei requisiti del successore all'attuale versione dell'Internet Protocol. Come conseguenza, gli stack del protocollo IPv6 devono includere IPsec. IPsec consente di autenticare, crittografare e comprimere qualsiasi tipo di traffico IP. A differenza dei protocolli a livello di applicazione, quali SSL o SSH, si può gestire tutto il traffico IP tra due nodi senza dover apportare modifiche alle applicazioni stesse. Il vantaggio di qeusto approccio è che tutte le applicazioni su una macchina possono beneficiare della crittografia e dell'autenticazione, e che le relative politiche possono essere impostate in modo generale a livello di host o anche di rete, e non semplicemente a livello di applicazione/servizio. Un'introduzione a IPsec comprendente anche i collegamenti alla documentazione si può trovare in [RFC2411], mentre il protocollo di base è descritto in [RFC2401].
9.1.7.3. Modifiche a IPv4
Ora che abbiamo visto le più importanti caratteristiche di IPv6 possiamo passare a esaminare le basi del protocollo. Per una migliore comprensione è preferibile una conoscenza elementare di IPv4, rispetto al quale saranno descritte le differenze. Inizieremo con gli indirizzi IPv6, spiegando come sono strutturati, quali sono i tipi di indirizzo e cosa ne è stato dei broadcast, e poi, dopo aver discusso lo "strato" IP, passerememo ai cambiamenti relativi alla risoluzione dei nomi e alle novità di IPv6 per il DNS.
9.1.7.3.1. Indirizzamento
Un indirizzo IPv4 è un valore a 32 bit, scritto solitamente nel formato denominato "dotted quad", dove ognuno dei valori separati dai punti è un valore compreso tra 0 e 255. Per esempio:
127.0.0.1
Questa struttura consente a un numero massimo teorico di 232 o ~4 miliardi di host di essere collegati all'attuale Internet. A causa dei raggruppamenti, però, non tutti gli indirizzi sono realmente disponibili.
Gli indirizzi IPv6 usano 128 bit, il che ci porta a 2128 host teoricamente indirizzabili. Questo consente di indirizzare un numero davvero enorme di macchine, coprendo completamente senza problemi tutti i requisiti attuali e futuri anche di PDA e telefoni cellulari dotati di indirizzo IP. Per scrivere gli indirizzi IP, li si divide in gruppi di 16 bit scritti con quattro cifre esadecimali, separando i gruppi con il carattere ":" (due punti). Per esempio:
fe80::2a0:d2ff:fea5:e9f5
Questo esempio mostra anche che una serie di zeri consecutivi può essere abbreviato con un unico "::" nel'indirizzo IPv6. L'indirizzo precedente è quindi equivalente a fe80:0:00:000:2a0:d2ff:fea5:e9f5. Gli zeri iniziali all'interno dei gruppi possono essere omessi.
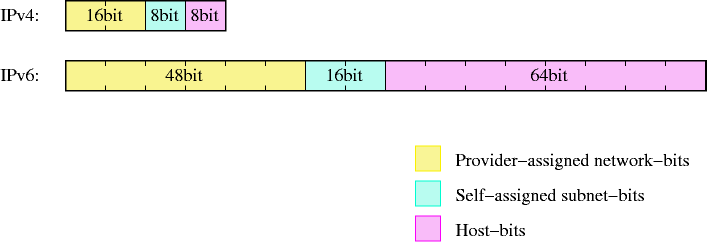
Per semplificarne la gestione, gli indirizzi vengono divisi in due parti: i bit che identificano la rete di appartenenza della macchina e i bit che identificano la macchina stessa sulla (sotto)rete. I primi vengono definiti "bit di rete" (netbits) e i secondi "bit di host" (hostbits) e, sia in IPv4 sia in IPv6, i bit di rete sono quelli più a sinistra (bit più significativi) mentre i bit di host sono quelli più a destra (bit meno significativi), come mostrato nella Figura 9-3.

In IPv4, i bit di rete e i bit di host vengono separati grazie alla maschera di rete. Esempi tipici sono 255.255.0.0, che usa 16 bit per l'indirizzo di rete, e 255.255.255.0, che usa altri 8 bit, consentendo, per esempio, di indirizzare 256 sottoreti su una rete di classe B.
Quando si è passati dall'indirizzamento per classi al formato CIDR, la separazione tra bit di rete e bit di host ha smesso di cadere necessariamente sul limite degli 8 bit e, in conseguenza, le maschere di rete hanno incominciato a essere più difficili da gestire. Al posto delle maschere si è quindi cominciato a indicare il limite usarndo il numero di bit di rete per un dato indirizzo; per esempio:
10.0.0.0/24
corrisponde a una maschera di rete di 255.255.255.0 (24 bit a 1). Lo stesso schema è usato in IPv6. Il valore:
2001:638:a01:2::/64
indica che nell'indirizzo specificato i primi 64 bit (quelli più a sinistra) riguardano la rete mentre gli ultimi 64 bit (quelli più a destra) identificano la macchina sulla rete. I bit di rete vengono spesso chiamati "prefisso" (di rete) e la lunghezza del prefisso è qui di 64 bit.
Tra i più comuni schemi di indirizzamento di IPv4, c'erano le reti di classe B e di classe C. Con una rete di classe C (/24), il provider assegna 24 bit, lasciandone 8 disponibili. Se si aggiungono delle sottoreti si finisce con l'avere una maschera di rete "irregolare" non molto pratica da gestire. In questo caso una rete di classe B (/16) sarebbe più facile da gestire perché dal provider vengono fissati solo 16 bit, il che consente di creare sottoreti con maggiore facilità dividendo in due parti i restanti 16 bit: la prima parte indirizza la sottorete locale e la seconda indirizza l'host all'interno della sottorete stessa. Solitamente si "spezza" sul confine degli otto bit (un byte); usando una maschera di rete di 255.255.255.0 (/24) si riescono a gestire in modo flessibile anche reti di grandi dimensioni, fermo restando il limite di 256 sottoreti di 254 macchine l'una.
Con i 128 bit disponibili per l'indirizzamento in IPv6, lo schema utilizzato è lo stesso, solamente con i campi più grossi. I provider solitamente assegnano reti /48, il che lascia 16 bit per le sottoreti e 64 bit per gli host.
Mentre lo spazio per le reti è le sottoreti sembra adeguato, l'uso di 64 bit per gli host appare uno spreco di spazio. Visto che è improbabile utilizzare svariati miliardi di host sulla stessa sottorete, perché isare questa struttura?
L'idea alla base di un indentificativo di host di lunghezza fissa di 64 bit, è che gli identificativi di host non vengono più assegnati manualmente come viene oggi fatto con IPv4. Invece, si raccomanda (è solo una raccomandazione, non un obbligo) di costruirli partendo dai cosiddetti indirizzi EUI64. Gli indirizzi EUI64 occupano, come dice il nome, 64 bit e derivano dall'indirizzo MAC della scheda di rete. Per esempio, per Ethernet, all'indirizzo di rete di 6 byte (48 bit) vengono solitamente solitamente aggiunti i bit "fffe" nel mezzo e un bit viene impostato per indicare che l'indirizzo è unico (il che è vero per Ethernet). Per esempio, l'indirizzo MAC
01:23:45:67:89:ab
diventa l'indirizzo EUI64
03:23:45:ff:fe:67:89:ab
il che porta i bit di host dell'indirizzo IPv6 a avere la forma
::0323:45ff:fe67:89ab
Questi bit di host possono essere usati per assegnare l'indirizzo IPv6 a un host, supportando l'autoconfigurazione degli host IPv6: tutto ciò che serve per avere un indirizzo IPv6 completo sono i primi bit (rete/sottorete), ma IPv6 offre anche il sistema per assegnarli automaticamente.
Sulle reti di macchine IP c'è solitamente un router che agisce da gateway verso le reti esterne. Nelle reti IPv6, il router invia una serie di informazioni di "router advertisement", che i client dovrebbero ricevere mentre sono in funzione oppure richiedere esplicitamente mentre sono in fase di avvio. Queste informazioni comprendono l'indirizzo del router e i prefissi di rete gestiti dal router stesso. Con queste informazioni e l'indirizzo EUI64 generato automaticamente, un host IPv6 può determinare il proprio indirizzo IP senza bisogno di assegnazione manuale. Naturalmente i router devono ancora essere configurati esplicitamente.
Le informazioni inviate dal router fanno parte del protocollo NDPNeighbor Discovery Protocol (vedere [RFC2461]), che è il successore del protocollo ARP dell'IPv4. A differenza di ARP, NDP non solo ricerca gli indirizzi IP corrispondenti agli indirizzi MAC, ma effettua anche un servizio simile per i router e i relativi prefissi di rete gestiti, il che viene utilizato per l'autoconfigurazione degli host IPv6 appena descritta.
9.1.7.3.2. Indirizzi multipli
Con IPv4, un host ha generalmente un indirizzo IP per ogni intrfaccia di rete o anche per macchina, se lo stack IP lo supporta. Solo alcune specifiche applicazioni, come i server web, richiedono macchine che hanno più di un indirizzo IP. Con IPv6 tutto ciò è diverso. Per ogni interfaccia, non solo c'è un indirizzo IP globale, ma ci sono anche altri due indirizzi interessanti: l'indirizzo "link local" e l'indirizzo "site local". L'indirizzo link local ha prefisso fe80::/64 e i bit di host derivano dall'indirizzo EUI64; esso viene usato solo per contattare gli host e i router sulla stessa rete e non è visibile o raggiungibile da altre sottoreti. Se lo si desidera, si può scegliere tra usare indirizzi globali (assegnati dal provider) oppure indirizzi site local; questi ultimi hanno l'indirizzo di rete fec0::/10 e le sottoreti e gli host possono essere indirizzati esattamente come nel caso delle reti assegnate dal provider. L'unica differenza è che l'indirizzo non sarà visibile dalle macchine esterne perché si trovano su una rete diversa e i loro indirizzi site local, se esistono, sono su una rete fisica diversa. Per IPv6 è pratica comune assegnare agli host l'indirizzo globale e quello link local. Gli indirizzi site local stanno diventando sempre più rari anche perché per la connettività globale è richiesto un indirizzo globale unico.
9.1.7.3.3. Multicasting
Nel dominio IP vi sono tre modi per raggiungere un host: unicast, broadcast e multicast. La forma più comune di colloquio sfrutta l'indirizzo unicast che, in IPv4, è il "normale" indirizzo IP assegnato a un host, comprendente i bit di rete. L'indirizzo di broadcast viene utilizzato per raggiungere tutti gli host sulla stessa sottorete IP e ha i bit di rete impostati all'indirizzo della rete e i bit di host tutti a "1". Gli indirizzi di tipo multicast servono per raggiungere gli host che fanno parte dello gruppo multicast, che possono trovarsi in un punto qualunque di Internet. Le macchine devono esplicitamente unirsi a un gruppo multicast pre poter partecipare, e vi sono indirizzi speciali IPv4 usati per il multicast, allocati sulla sottorete 224/8. Il multicast non viene molto utilizzato sotto IPv4; solo alcune applicazioni quali le utility MBone audio e video broadcast lo usano.
Gli indirizzi unicast IPv6 si usano allo stesso modo di quelli IPv4; nessun cambiamento, quindi - tutti i bit di rete e di host vengono assegnati per indentificare la rete e la macchina. Il broadcast non è più disponibile in IPv6 nel modo in cui lo era in IPv4: è qui che entra in gioco il multicasting. Gli indirizzi della rete ff::/8 sono riservati alle applicazioni multicast, e vi sono due speciali indirizzi mulicast che prendono il posto dell'indirizzo di broadcast di IPv4. Uno è l'indirizzo multicast "all routers" (tutti i router) e l'altro è "all hosts" (tutti gli host). Questi indirizzi sono specifici della sottorete, cioè un router collegato a due diverse sottoreti può indirizzare tutti gli host/router di una qualsiasi delle due sottoreti. In questo caso gli indirizzi sono:
ff0X::1 per tutti gli host
ff0X::2 per tutti i router
dove "X" è l'ID del collegamento, che identifica la rete e che, solitamente, inizia da "1" per l'ambito locale, "2" per il primo link, ecc. Si noti che è possibile che due interfacce di rete siano attaccate allo stesso link, risultando in un'ampiezza di rete doppia.
Un uso dell'indirizzo di multicast "all hosts" è nel codice NDP, quando una macchina che vuole comunicare con un'altra macchina invia una richiesta al gruppo all hosts e la macchina in questione deve rispondere.
9.1.7.3.4. La risoluzione dei nomi in IPv6
Dopo questa lunga introduzione all'indirizzamento sotto IPv6, è lecito sperare che vi sia un modo per continuare a usare dei nomi per riferirsi agli host, come si fa con IPv4, anziché snocciolare quei lunghi indirizzi IPv6. Naturalemente è possibile.
La traduzione da nome di host a indirizzo IP in IPv4 solitamente si fa in uno di questi tre modi: usando una semplice tabella in /etc/hosts, usando il Network Information Service (NIS, già YP) o con il Domain Name System (DNS).
Al momento, NIS/NIS+ su IPv6 è disponibile solo sotto Solaris 8, sia per il contenuto del database sia per il trasporto, usando una estensione RPC.
Una semplice mappa del tipo indirizzo<->nome, del tipo di /etc/hosts è supportata da tutti gli stack IPv6. Con l'implementazione KAME usata da NetBSD, il file /etc/hosts contiene sia gli indirizzi IPv4 sia quelli IPv6. A titolo di semplice esempio, vediamo la voce "localhost" nella versione di default per un'installazione di NetBSD.
127.0.0.1 localhost ::1 localhost
Per il DNS non vengono introdotti fondamentalmente nuovi concetti. La risoluzione dei nomi IPv6 viene fatta con record di tipo AAAA che, come indica il nome, puntano a un'entità che è quattro volte più grossa di un record di tipo A. Un record AAAA ha un nome di host nella parte sinistra, proprio com per A, e l'indirizzo IPv6 nella parte destra. Per esempio:
noon IN AAAA 3ffe:400:430:2:240:95ff:fe40:4385
Per la risoluzione inversa IPv4 usa la zona in-addr.arpa, alla quale aggiunge i byte (decimali) in ordine inverso, cioè con i byte più significativi più a destra. Com IPv6 il metodo è lo stesso, solo che vengono usate le cifre esadecimali (una ogni 4 bit) anziché i numeri decimali e i record delle risorse si trovano in un dominio differente, ip6.int.
Pertanto, per la risoluzione inversa dell'host precedente si deve mettere nel file /etc/named.conf una voce simile alla seguente:
zone "0.3.4.0.0.0.4.0.e.f.f.3.IP6.INT" {
type master;
file "db.reverse";}; e, nel file di zona db.reverse, oltre ai soliti record SOA e NS:
5.8.3.4.0.4.e.f.f.f.5.9.0.4.2.0.2.0.0.0 IN PTR noon.ipv6.example.com.
Qui l'indirizzo viene scritto una cifra esadecimale alla volta in ordine inverso, iniziando da quella meno significativa (quella più a destra) e separando le cifre con punti, come nei soliti file di zona.
Quando si imposta il DNS per IPv6 bisogna fare attenzione alla versione del software DNS che si utilizza. BIND 8.x capisce i record AAAA ma non offre la risoluzione dei nomi via IPv6; per questo è necessario utilizzare BIND 9.x che, tra l'altro, supporta alcuni tipi di record di risorsa ancora in fase di discussione e quindi non ufficialmente introdotti. Il più interessante è il record A6, che facilita il cambiamento di provider/prefisso.
Per riassumere, in questa sezione sono state discusse le differenze tecniche tra IPv4 e IPv6 per l'indirizzamento e la risoluzione dei nomi. Alcuni aspetti, quali le opzioni delle testate IP, QoS, ecc. non sono volutamente stati trattati per non appesantire troppo la materia, visto anche il carattere introduttivo di questa guida.
Bibliography
[RFC1055] J. L. Romkey, 1988, RFC 1055: Nonstandard for transmission of IP datagrams over serial lines: SLIP.
[RFC1331] W. Simpson, 1992, RFC 1331: The Point-to-Point Protocol (PPP) for the Transmission of Multi-protocol Datagrams over Point-to-Point Links.
[RFC1933] R. Gilligan e E. Nordmark, 1996, RFC 1933: Transition Mechanisms for IPv6 Hosts and Routers.
[RFC2461] T. Narten, E. Nordmark, e W. Simpson, 1998, RFC 2461: Neighbor Discovery for IP Version 6 (IPv6).
[RFC2529] B. Carpenter e C. Jung, 1999, RFC 2529: Transmission of IPv6 over IPv4 Domains without Explicit Tunnels.