Capítulo 9. Introdução às redes TCP/IP
- Índice
- 9.1. Redes TCP/IP
- Bibliografia
9.1. Redes TCP/IP
O autor deste capítulo (Introdução às redes TCP/IP) é Hubert Feyrer <hubert@feyrer.de>.
9.1.1. Introdução
O presente capítulo do guia é dedicado às redes, das quais explica os elementos fundamentais para os leitores que não têm uma grande familiaridade com o assunto. O capítulo seguinte, por sua vez, contém uma introdução prática às configurações de rede do NetBSD. Quem deseja configurar rapidamente a rede pode iniciar com o próximo capítulo e depois voltar vom calma à leitura do capítulo atual.
Da parte do leitor é pressuposto o conhecimento de elementos de base da administração do sistema: como tornar-se "root", como editar arquivos, como mudar as permissões dos arquivos, como encerrar processos, etc. Ver por exemplo [AeleenFrisch] para aprofundar estas questões. Além disso, é necessário saber utilizar alguns programas utilitários como telnet, ftp, etc. Tais programas não serão descritos aqui e, portanto, para informações adicionais remete-se às páginas de manual, à bibliografia e aos outros capítulos desse guia.
Esta introdução às redes TCP/IP não tem a pretensão de ser completa. Quem deseja aprofundar os assuntos tratados, para ter um quadro mais completo pode fazer referência a [CraigHunt]. Este livro, além de descrever os elementos de base, explica todos os conceitos e detalhes necessários para a configuração de todos os serviços. É um ótimo livro.
9.1.2. Protocolos de rede suportados
O NetBSD suporta vários protocolos de rede, a maior parte dos quais herdados de seu predecessor, o 4.4BSD, e posteriormente estendidos e melhorados. O primeiro protocolo implementado é o que hoje tem maior importância, o Transmission Control Protocol/Internet Protocol (TCP/IP) do DARPA. Outros protocolos disponíveis no NetBSD são o Xerox Network System (XNS), implementado para a UCB para coligar em rede máquinas isoladas, o AppleTalk da Apple, o ISO, o CCITT X.25 e o ARGO TP. Estes últimos protocolos são usados hoje apenas para algumas aplicações especiais.
Hoje o TCP/IP é o protocolo mais difundido entre os mencionados no parágrafo precedente. Além de ser implementado para todo sistema operacional e em todo tipo de hardware, é também o protocolo mais usado em ambientes heterogêneos. Portanto, o TCP/IP é a escolha mais justa para conectar seu próprio computador a outras máquinas domésticas ou a redes empresariais ou universitárias.
A versão corrente do protocolo TCP/IP é a 4 (IPv4). A versão 6 (IPv6) está em fase de desenvolvimento e o código IPv6 do projeto KAME está integrado nas edições do NetBSD já a partir da 1.5.
Também existem protocolos que não são suportados pelo NetBSD, como DECNET, IPX/SPX da Novell e NetBIOS da Microsoft. Estes protocolos, diferentemente dos precedentes, são proprietários e, portanto, não são definidos por algum RFC público como os outros padrões abertos.
9.1.3. Interfaces suportadas
O protocolo TCP/IP pode ser utilizado com uma ampla gama de interfaces. Entre as suportadas pelo NetBSD recordemos a Ethernet (10/100/1000MBd), a linha serial Arcnet, ATM, Fiber Channel, USB, HIPPI, FireWire (IEEE 1394), Token Ring, linhas seriais e ainda outras.
9.1.3.1. Linhas seriais
Há várias razões que nos levam a aconselhar o uso de TCP/IP em linhas seriais.
se um host remoto é acessável apenas por telefone, pode-se contatá-lo por modem.
praticamente todos os computadores dispõem de uma saída serial e o cabo necessário é muito barato.
A desvantagem das conexões por linha serial é que são mais lentas que os outros métodos. Nessa conexão o NetBSD pode utilizar no máximo 115300 bit/s, o que a torna muito mais lenta em comparação com os 10 Mbit/s da Ethernet e aos 4 Mbit/s do Arcnet.
Para conectar um host com NetBSD a um outro host por via serial, eventualmente também por linha telefônica, podem-se usar dois métodos:
Serial Line IP (SLIP)
Point to Point Protocol (PPP)
A escolha depende do tipo de conexão que se quer efetuar. Para uma conexão telefônica por modem, convém utilizar o PPP, que oferece a opção de auto-negociar os endereços IP e trajetos (routes), coisas complicadas de configurar manualmente. Ao contrário, para conectar-se diretamente a uma outra máquina, por exemplo com um cabo null-modem ou uma linha dedicada, o protocolo SLIP é mais simples de configurar com endereços e trajetos (routes), e é suportado praticamente por todos os sistemas operacionais.
PPP em uma linha direta é mais difícil de configurar se compararmos com SLIP por causa do handshake inicial, que no SLIP não está presente. Isto significa que com o SLIP inicia-se a conexão de um lado e o outro lado já pode enviar o primeiro pacote assim que estiver pronto.
[RFC1331] e [RFC1332] descrevem os protocolos PPP e TCP/IP em PPP. SLIP é descrito em [RFC1055].
9.1.3.2. Ethernet
Ethernet é a interface mais utilizada no âmbito das redes locais LAN (Local Area Network) de máquinas interconectadas em uma área limitada, que pode ser um escritório, uma empresa ou uma universidade. Ethernet baseia-se em um bus a que várias máquinas podem conectar-se e a comunicação ocorre sempre entre dois nódulos (nodes) por vez. Quando vários pares de nódulos tentam comunicar-se ao mesmo tempo, verifica-se um conflito e os pares procurarão comunicar-se de novo ao fim de um prazo (timeout). O termo técnico utilizado para esse procedimento é CSMA/CD (Carrier Sense w/ Multiple Access and Collision Detection).
Inicialmente o hardware Ethernet consistia em um grosso cabo (amarelo) que era ligado às máquinas usando conectores especiais que furavam a camada de proteção externa do próprio cabo. Posteriormente chegou o tipo 10base5, que usava conectores do tipo BNC para inserir em conectores especiais em T da própria máquina, com terminais em ambas as extremidades da linha. Hoje o bus ethernet está contido dentro dos comutadores (switches) e dos hubs, e os cabos são do tipo twisted pair, dando o nome a este tipo de interface: 10baseT para as redes a 10 Mbit/s e 100baseT para as redes a 100Mbit/s. Nas redes configuradas com switch distinguem-se os dois casos em que a comunicação entre nódulo e switch ocorre em modo full-duplex ou half-duplex.
9.1.4. O formato dos endereços TCP/IP
A atual implementação do protocolo TCP/IP (IPv4) usa os identificadores de 4 bytes (32 bits) (chamados também endereços de IP) para endereçar os hosts.
Estes endereços IP são únicos em nível mundial. Para atingir esse objetivo, sua administração é delegada a um organismo central, o InterNIC, que designa grupos de endereços diretamente aos sites que queiram ligar-se à Internet ou aos provedores que os redistribuirão aos próprios clientes.
As universidades e empresas ligadas à Internet têm pelo menos um desses endereços, geralmente não atribuído diretamente pelo InterNIC, mas obtido de um Provedor de Serviço de Internet (Internet Service Provider ISP).
Para configurar uma rede privada doméstica basta "inventar" os próprios endereços privados, como se explica à frente. Para conectar a própria máquina à Internet, todavia, é necessário obter um "verdadeiro" endereço de IP do próprio administrador de rede ou do provedor.
Para a escrita dos endereços IP é usada particularmente uma notação chamada dotted quad (quadripontuada), na qual os quatro bytes do endereço são escritos um de cada vez (a partir do mais significativo), separando-os com um ponto. Por exemplo 132.199.15.99 é um endereço válido. Um endereço pode também ser escrito utilizando-se uma palavra de 32 bits em hexadecimal, por exemplo: 0x84c70f63. Este formato não é tão intuitivo como o precedente, mas às vezes pode-se revelar útil como será visto nas seções seguintes.
Atribuir uma rede a um host significa simplesmente estabelecer valores determinados para alguns dos 32 bits do endereço do host. Estes bits, usados para identificar a rede, são chamados "bits de rede". Os bits restantes servem para identificar o host no interior da rede, e são portanto denominados "bits de host".
No exemplo precedente o endereço de rede é 132.199.0.0 (em um endereço de rede os bits de host são definidos como zero), enquanto o endereço do host na rede é 15.99.
Como se faz para saber que o endereço do host ocupa 16 bits? Simples: é indicado pelo provedor do qual se obtém o próprio endereço. No estradamento inter-domínios sem classificação (Classless Inter-Domain Routing,CIDR) utilizado hoje, o número de bits reservados ao host vai de 2 a 16 e o número de bits reservado à rede é escrito depois do endereço IP, separado por uma "/". Por exemplo, 132.199.0.0/16 indica que a rede em questão tem 16 bits. Quando nos referimos à "dimensão" de uma rede, o fazemos em geral simplesmente com "/16", "/24", etc.
Antes do advento do CIDR as redes eram divididas em quatro classes. Cada classe iniciava-se com uma bem precisa seqüência de bits que a identificava. Em detalhe:
A Classe A inicia-se com "0" como o bit mais significativo. Os próximos 7 bits de um endereço de Classe A identificam a rede e os restantes 24 bits são usados para endereçar o host. Portanto, em uma rede de Classe A pode haver um host 224. Não é fácil, todavia, para uma firma ou para uma universidade obter um endereço de Classe A completo.
A notação CIDR para uma rede de Classe A com os seus 8 bits de rede é "/8".
A Classe B inicia-se com "10" como os bits mais significativos. Os próximos 14 bits identificam a rede e os restantes 16 bits servem para endereçar os hosts (mais de 65000). Os endereços de Classe B, que já foram muito comuns para firmas e universidades, são hoje muito difíceis de se obter, por causa da atual escassez de endereços IPv4 disponíveis.
A notação CIDR para uma rede de Classe A com os seus 16 bits de rede é "/16".
Retornando ao exemplo precedente, pode-se ver que o host 132.199.15.99 (ou o equivalente hexadecimal 0x84c70f63, que aqui é mais cômodo) encontra-se em uma rede de Classe B, já que 0x84 = 1000... (em binário).
Portanto, o endereço 132.199.15.99 pode ser dividido na parte de rede que é 132.199.0.0 e na parte do host que é 15.99.
A Classe C é identificada pelos bits mais significativos (chamados também MSB, Most Significant Bits) iguais a "110", permitindo apenas 256 hosts em cada uma das 221 possíveis redes de Classe C (na realidade, como será visto depois, o número de hosts possíveis é 254). Os endereços de Classe C são mais comumente encontrados em pequenas empresas.
A notação CIDR para uma rede de classe C com os seus 24 bits de rede é "/24".
Existe também uma ulterior série de endereços que se iniciam com "111", e que são muito usados para outros fins (por exemplo, multicast) e que não nos interessam aqui.
Note-se que os bits utilizados para identificar a rede fazem, não obstante, parte do próprio endereço de rede.
Quando se separa a parte de rede da parte de host é cômodo utilizar a assim chamada netmask (máscara de rede). Trata-se de um valor a ser usado como "mascára", em que todos os bits de rede são assentados em "1" e todos os bits de host em "0". Pondo juntos com um AND lógico o endereço com a netmask obtém-se o endereço da rede.
Reportando-se ao exemplo precedente, 255.255.0.0 é uma possível netmask de 132.199.15.99. Quando se aplica a netmask ao endereço, permanece a parte de rede 132.199.0.0.
Para os endereços em notação CIDR, o número indicado de bits de rede especifica também quais dos bits mais significativos devem ser postos em "1" para se obter a netmask da rede correspondente. Para os endereços de rede Classe A/B/C existe uma netmask default:
Class A (/8): netmask default: 255.0.0.0, primeiro byte do endereço: 1-127
Class B (/16): netmask default: 255.255.0.0, primeiro byte do endereço: 128-191
Class C (/24): netmask default: 255.255.255.0, primeiro byte do endereço: 192-223
Um tipo particular de endereço que é bom conhecer é o "endereço de broadcast". As mensagens enviadas a este endereço são recebidas por todos os hosts da rede correspondente. O endereço de broadcast é caracterizado pelo fato de ter todos os bits de host colocados em "1".
Por exemplo, dado o endereço 132.199.15.99 com a máscara de rede 255.255.0.0, o endereço de broadcast é 132.199.255.255.
Nesse ponto podem-nos perguntar se podemos utilizar um endereço de host com todos os bits em "0" ou em "1". A resposta é não, porque o primeiro é o endereço da rede e o segundo o endereço de broadcast, e esses dois endereços devem estar sempre presentes. Agora se pode compreender porque uma rede de Classe B pode conter no máximo 216-2 hosts e uma rede de Classe C pode conter 28-2 = 254.
Além dos vários tipos de endereço já citados, há um outro que é especial. Trata-se do endereço 127.0.0.1, que se refere sempre ao host local (localhost). Isso significa que quando se "fala" com o 127.0.0.1, comunica-se na realidade consigo mesmo, sem dar lugar a nenhuma atividade de rede, o que pode ser útil para utilizar os serviços instalados na própria máquina ou para fazer simulações e testes quando não há outro host na rede.
Resumindo o que se discutiu até agora:
- Endereço IP
endereço de 32 bits, comprendendo a parte de rede e a parte do host.
- Endereço de rede
endereço IP com todos os bits de host postos em "0".
- Netmask (máscara de rede)
máscara de 32 bits em que os bits que se referem à rede são colocados em "1", enquanto os que se referem ao host são postos em "0".
- Endereço de broadcast
endereço IP com todos os bits de host postos em "1".
- Localhost
o endereço IP do host local. É sempre 127.0.0.1
9.1.5. Sub-rede e estradamento (routing)
A seção precedente descreveu em detalhe as máscaras de rede e os endereços de host e de rede. O discurso sobre redes, entretanto, está longe de terminar.
Consideremos a situação de uma típica universidade, com um endereço de Classe B (/16) que lhe permite ter até 216 ~= 65534 hosts na rede. Mesmo que fôsse cômodo pensarmos em ter todos estes hosts em uma mesma rede, isto não pode ser realizado por causa das limitações físicas do hardware em uso atualmente.
Por exemplo, o comprimento máximo de um cabo Ethernet thinwire é de 185 metros. Ainda que se ponham repetidores que amplifiquem o sinal entre os pontos de rede, isto não basta para se atingir todos os pontos de rede em que se encontram as máquinas. Além disso, o número máximo de hosts em um cabo Ethernet thinwire é de 1024 e, avizinhando-se desse limite, tem-se uma perda de eficiência.
Portanto, encontramo-nos em uma situação em que temos um endereço que permitiria ter 60000 hosts mas estamos limitados pelo cabeamento, que nos permite atingir um número muito menor de pontos de rede.
Naturalmente existe a solução, e consiste em subdividir a "rede" de Classe B em redes menores, usualmente denominadas sub-redes. Estas sub-redes podem hospedar, por exemplo, até 254 hosts cada (isto é, subdividimos a grande rede de Classe B em várias sub-redes de Classe C).
Para se obter esse resultado, é necessário modificar a máscara de rede para se ter mais bits de rede e menos bits de host. Isto geralmente se faz trabalhando sobre os bytes da máscara (mesmo que seja possível descer ao nível de um único bit). Portanto, a coisa mais simples é transformar a máscara de rede de 255.255.0.0 (Classe B) em 255.255.255.0 (Classe C).
Usando a notação CIDR, escreve-se agora "/24" ao invés do precedente "/16" para indicar que são usados 24 bits do endereço para identificar a rede e a sub-rede,em vez dos 16 usados antes.
Esta modificação permite-nos ter um byte de rede a mais para cada uma das redes físicas. Todos os 254 hosts de cada rede podem comunicar-se diretamente e podem ser criadas 256 redes desse tipo (Classe C). Esta nova configuração deveria ser adequada às exigências da nossa universidade hipotética.
Para esclarecer melhor o conceito, continuemos com o exemplo precedente. Suponhamos que o nosso host seja 132.199.15.99, que se chame dusk e que tenha a netmask 255.255.255.0, o que significa que se encontra na sub-rede 132.199.15.0/24. Naturalmente há outros hosts,como se vê pela Figura 9-1.
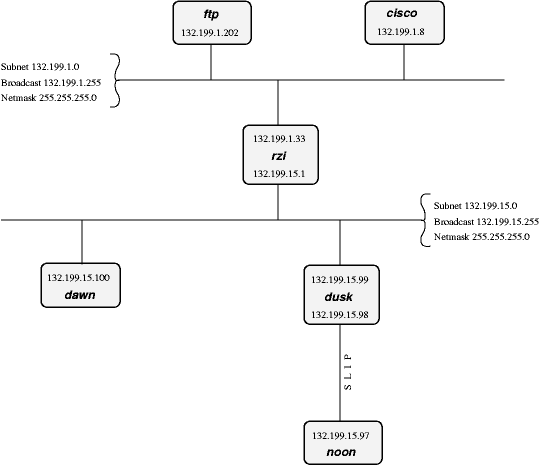
Na rede do exemplo,dusk pode falar diretamente com dawn, já que ambos encontram-se na mesma sub-rede. Existem ainda outros hosts na sub-rede 132.199.15.0/24, mas por ora não os consideraremos.
O que acontece se dusk quer falar com um host que se encontra em uma outra sub-rede? Nesse caso, o tráfego ocorrerá através de um ou mais gateways (routers) anexados às duas sub-redes. Por esse motivo um gateway tem sempre dois endereços diferentes: um para cada uma das subredes a que está conectado. Do ponto de vista funcional, o router (estradador) é totalmente transparente para os hosts. Ou seja, não é necessário conhecer-lhe o endereço para atingir os hosts que estão do "outro lado". É suficiente endereçar diretamente aos hosts e os pacotes alcançarão o destino correto.
Suponhamos por exemplo que dusk queira fazer o download de arquivos do servidor FTP local. Já que dusk não pode alcançar ftp diretamente (porque se encontra em uma sub-rede diferente) todos os seus pacotes serão encaminhados ao seu "router por default" rzi (132.199.15.1), que sabe para onde deve enviá-los para que atinjam a destinação.
dusk conhece o endereço do router por default da sua rede (rzi, 132.199.15.1), e lhe encaminha todos os pacotes que não são destinados à mesma sub-rede. Isto é, neste caso, todos os pacotes IP que têm o terceiro byte do endereço diferente de 15.
O router por default (defaultrouter) envia os pacotes ao host apropriado, visto que se encontra na sub-rede do servidor de FTP.
Neste exemplo todos os pacotes são enviados à rede 132.199.1.0/24 simplesmente porque se trata do backbone da rede, a parte mais importante da rede, que transporta todo o tráfego de passagem entre as várias sub-redes. Quase todas as sub-redes além de 132.199.1.0/24 estão conectadas ao backbone de modo similar.
Que acontece se conectássemos uma outra sub-rede a 132.199.15.0/24 ao invés de 132.199.1.0/24? Provavelmente algumas coisa parecida à situação descrita na Figura 9-2.
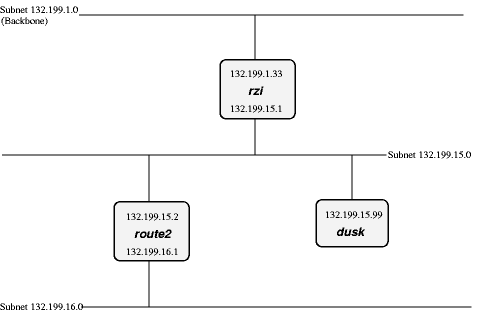
Agora, para dusk atingir um host que se encontra na sub-rede 132.199.16.0/24, os pacotes não podem ser encaminhados a rzi. É necessário enviá-los diretamente a route2 (132.199.15.2). dusk deve saber que deve encaminhar estes pacotes para route2 e enviar todos os outros para rzi.
Quando se configura dusk, dizemos a ele para enviar todos os pacotes para a sub-rede 132.199.16.0/24, a route2, e todos os outros a rzi. Ao invés de explicitar este default com 132.199.1.0/24, 132.199.2.0/24, etc., pode-se usar o valor 0.0.0.0 para definir a rota default.
Retornando à Figura 9-1, verifica-se um problema parecido quando dawn quer enviar a noon, que está ligado a dusk via cabo serial. Do exame de seu endereço IP,noon pareceria estar conectado à rede 132.199.15.0. Esse realmente não é o caso. Ao contrário, dusk é usado como gateway e dawn deve enviar seus pacotes a dusk que, por sua vez, os encaminhará a noon. O sistema graças ao qual dusk é forçado a aceitar pacotes que não são destinados a ele, mas a um outro host (noon), é definido "proxy arp".
O mesmo discurso vale quando um host de uma outra sub-rede que enviar a noon. Deverá enviar os seus pacotes a dusk (eventualmente encaminhados por rzi).
9.1.6. Conceitos de Name Service
Nas seções precedentes, fazendo referência aos hosts utilizamos freqüentemente seus endereços IP. Isto era necessário para explicar as diferenças entre os vários tipos de endereços. Em geral, todavia, quando se fala de host é mais cômodo utilizar seu "nome", como fizemos na seção sobre routing.
Para a maior parte das aplicações não importa se os hosts são especificados usando o nome ou o endereço IP. Todavia, internamente elas usam endereços IP. Nesta seção serão introduzidos os conceitos que estão na base de cada um desses métodos. Sucessivamente será explicado como efetuar-lhes a configuração.
A conversão dos nomes dos hosts (e dos domínios) em endereços de IP é realizada por um módulo de software chamado resolver. Não se trata de um serviço complementar, mas de uma série de funções de biblioteca que são articuladas com cada aplicação que usa funções de rede. O resolver procura "resolver" (daí o nome) os nomes dos hosts em endereços IP. Veja-se [RFC1034] e [RFC1035] para maiores detalhes sobre o resolver.
Os nomes dos hosts têm geralmente um comprimento máximo de 10 caracteres e podem conter letras, números, hífens ("-") e traços de subscrito ("_"). Maiúsculas e minúsculas são consideradas equivalentes.
Assim como para as redes e sub-redes, é possível (mais que isso, desejável) reagrupar os hosts em domínios e subdomínios. Quando se obtém um endereço de rede do provedor, geralmente se obtém também um nome de domínio. Como para as sub-redes, é deixada ao usuário a tarefa de criar sub-domínios. Os sub-domínios não estão em relação direta com as sub-redes. Por exemplo, um domínio pode conter hosts conectados a diversas sub-redes.
Figura 9-1 mostra as sub-redes 132.199.1.0/24 e 132.199.15.0/24 (e as outras) que fazem parte do sub-domínio rz.uni-regensburg.de. O domínio que a Universidade de Regensburg obteve de seu provedor de IP é "uni-regensburg.de" (".de" indica a Alemanha, Deutschland); o sub-domínio "rz" indica Rechenzentrum (Centro de Cálculo).
Os nomes dos hosts, dos sub-domínios e dos domínios são separados por pontos (".". Também é possível, embora não seja comum, usar mais de um nível de sub-domínio. Por exemplo: fox_in.socs.uts.edu.au.
Um nome de host que compreende o (sub)domínio é denominado domínio completamente qualificado (FQDN, Fully Qualified Domain Name). Por exemplo, o endereço IP 132.199.15.99 pertence ao host cujo FQDN é dusk.rz.uni-regensburg.de.
Anteriormente foi dito que o endereço IP 127.0.0.1 pertence sempre ao host local, qualquer que seja o "verdadeiro" endereço IP do próprio host. Portanto, 127.0.0.1 é sempre mapeado pelo nome localhost.
Os três métodos diferentes de traduzir um nome de host em endereço IP são: /etc/hosts, o Domain Name Service (DNS) e o Network Information Service (NIS).
9.1.6.1. /etc/hosts
O primeiro e mais simples dos três métodos para traduzir um nome de host para endereço IP consiste no uso de uma tabela que põe em correspondência os nomes e os endereços correspondentes. Esta tabela encontra-se no arquivo /etc/hosts e tem o seguinte formato:
endereço IP nome host [alias [...]]
As linhas que se iniciam com um sustenido (cerquinha) ("#") são considerados comentários e são ignoradas. As outras linhas contêm um endereço IP e o/os correspondentes nomes de host.
Não é possível que um nome de host corresponda a mais de um endereço IP. rzi, por exemplo, tem dois nomes diferentes para os seus dois endereços: rzi e rzia.
Pode ser cômodo dar vários nomes (alias) a um host. Isto permite especificar um nome alternativo para o host em relação a um serviço particular, como é feito, por exemplo, com o servidor de FTP. O primeiro nome (o mais à esquerda) é usualmente o nome real (canônico) do host.
Também pode ser útil usar o nome completo (FQDN) do host como nome canônico, e o seu hostname (sem o domínio) como alias.
Importante: devemos sempre convencionar o mapping do localhost em 127.0.0.1!
9.1.6.2. O Domain Name Service (DNS)
O uso do /etc/hosts comporta um problema, especialmente nas redes de grandes dimensões: quando se acrescenta um host ou se altera o endereço de um host, todos os arquivos etc/hosts de todas as máquinas devem ser atualizadas. Isso não só implica uma perda de tempo, mas também é uma possível causa de erros e inconsistências que inevitavelmente trarão problemas.
Um outro método é manter uma só tabela de nomes de hosts (banco de dados) para a rede inteira e fazer com que todos os clientes interroguem esse "nameserver".
Esta é a idéia de base sobre a qual se funda o Domain Name Service (DNS).
Usualmente há um servidor de nomes para cada domínio (daí o nome Domain Name Server) e cada host no domínio sabe a qual domínio pertence e qual servidor de nomes deve interrogar para seu próprio domínio.
Quando o DNS recebe uma interrogação para um host que não se encontra em seu domínio a encaminha ao DNS do domínio correspondente ou a um DNS que sabe a qual DNS solicitar a informação. Este último encaminha a interrogação a um DNS de nível superior e assim por diante. Este processo não vai adiante ao infinito. Há vários servidores "root" que possuem as informações de todos os domínios.
Ver Capítulo 11 para maiores detalhes sobre o DNS.
9.1.6.3. O Network Information Service (NIS/YP)
A Yellow Pages (YP) foram inventadas pela Sun Microsystems. O nome depois foi mudado para Network Information Service (NIS) porque YP já era uma marca da British Telecom.
Nos sistemas Unix estão habitualmente presentes um grande número de configurações e é, portanto, muito desejável limitar a manutenção destes arquivos a uns poucos hosts. Os hosts são, assim, agrupados em domínios NIS (que não têm nada a ver com os domínios DNS) e em geral fazem parte de um cluster (cacho) de workstations.
Alguns dos arquivos de configuração compartilhados por estes hosts são /etc/passwd, /etc/group e /etc/hosts.
É, portanto, possível "abusar" do NIS para obter uma única tradução de nomes para endereços em todos os hosts de um domínio NIS.
Há apenas uma desvantagem que impede ao NIS de ser efetivamente utilizado para esse tipo de tradução: diferentemente do DNS, o NIS não fornece nenhum método para resolver os nomes dos hosts que não fazem parte da tabela dos hosts. Não existem hosts de nível superior que o servidor NIS possa interrogar e, portanto, a tradução fica fadada ao fracasso. O NIS+, também da Sun, resolve esse problema, mas como o NIS+ está disponível apenas para os sistemas Solaris, não nos será de grande ajuda.
Do que foi dito não quer dizer que o NIS não seja um método excelente para gerenciar, por exemplo, as informações sobre os usuários (/etc/passwd, ...) em clusters de workstations. Simplesmente não é muito útil para resolver os nomes dos hosts.
9.1.6.4. Outros métodos
Os métodos descritos até aqui para a resolução dos nomes dos hosts em endereços IP são aqueles atualmente de uso mais comum, mas não são os únicos. Por definição pode-se utilizar um banco de dados qualquer, mas não há desenvolvimentos desse tipo no NetBSD.
O NIS+, como já foi dito, procura remediar a falta de hierarquia nas estruturas de dados do NIS. As tabelas podem ser estabelecidas de modo que se uma interrogação não puder ser satisfeita pelo servidor de um domínio, pode haver um outro domínio de nível superior em condição de dar uma resposta. Por exemplo, pode-se definir um domínio que relacione todos os hosts (usuários, grupos, etc.) pertencentes a uma firma inteira, um outro que define os mesmos dados para cada divisão, e assim por diante. O NIS+ não é atualmente muito usado. Até a própria Sun retomou o fornecimento do NIS inicial.
No passado, o padrão X.500 foi projetado para gerenciar bancos de dados simples, como o arquivo /etc/hosts, e estruturas hierárquicas complexas, como por exemplo o atual DNS. O X.500 jamais teve muito sucesso, em parte porque tentava fazer muitas coisas ao mesmo tempo. Uma versão reduzida chamada LAP (Lightweight Directory Access Protocol) está hoje disponível e a popularidade está crescendo nos últimos anos, para gerir os dados dos usuários (mas também dos hosts) em organizações de pequenas e médias proporções.
9.1.7. IPv6, o protocolo de última geração da Internet
9.1.7.1. O futuro da Internet
A juízo dos experts, a Internet na sua forma atual deverá enfrentar um problema sério dentro de poucos anos. Por causa de seu rápido crescimento e das limitações em seu projeto, chegar-se-á a um ponto em que não estarão mais disponíveis endereços para conter novos hosts. Nesse momento, não se poderão acrescentar novos servidores da web, os usuários não poderão obter contas dos ISPs, não se poderão conectar novas máquinas em rede para acessar a web ou participar de jogos online. Em resumo, um problema muito sério.
Foram pensadas várias abordagens para resolver este problema. Um método muito difundido consiste em não atribuir endereço válido unívoco para cada máquina conectada, mas atribuir endereços "privados" e "esconder" várias máquinas por trás de um único endereço oficial global. Este método, que se chama Network Address Translation (NAT, conhecido ainda como IP Masquerading), apresenta problemas porque as máquinas escondidas atrás do endereço único global não podem ser endereçadas diretamente e, portanto, não é possível abrir conexões com elas, como exigido, por exemplo, pelos jogos online, pelas redes peer-to-peer, etc. Para uma discussão sobre as desvantagens do NAT, ver [RFC3027].
Uma abordagem diferente ao problema da escassez de endereços da Internet é abandonar o velho protocolo da Internet e a sua limitada capacidade de endereçamento, em favor de um novo protocolo que não sofre estas limitações. O protocolo, ou melhor, o conjunto de protocolos usado pelas máquinas conectadas para formar a atual Internet é conhecido como suite TCP/IP (Transmission Control Protocol/Internet Protocol), e a sua versão 4, a que está em uso atualmente, tem todos os problemas descritos há pouco. Para poder passar a uma nova versão do protocolo que resolva esses problemas é necessário, obviamente, que a tal versão "melhor" exista. De fato, a versão 6 do Internet Protocol (IPv6) existe e responde a todas as possíveis exigências futuras de espaço de endereçamento, enfrentando ainda outros problemas como a segurança de dados, a criptografia e um suporte melhor à computação móvel.
Esta seção introduz o protocolo IPv6. Para uma boa compreensão será exigido um conhecimento básico do funcionamento do protocolo IPv4. São descritas as mudanças no formato do endereço e na resolução dos nomes. Usufruindo dessas informações, a Secçăo 10.2.4 mostrará como utilizar o IPv6 mesmo se ele não for oferecido pelo ISP, utilizando um mecanismo de transição simples mas eficaz denominado 6to4. O objetivo final será por-se online com o IPv6, mostrando um exemplo de configuração do NetBSD.
9.1.7.2. Por que passar ao IPv6?
Quando se aconselha alguém a passar do IPv4 para o IPv6, a primeira pergunta que se ouve em retorno é: "por que"? Há várias boas razões.
Maior espaço de endereçamento.
Suporte à "mobile computing".
Gestão integrada da segurança.
9.1.7.2.1. Maior espaço de endereçamento
A ampliação do espaço de endereçamento oferecido é a primeira das vantagens oferecidas pelo IPv6 em comparação com o IPv4. A atual arquitetura da Internet está baseada em endereços de 32 bits, enquanto que a nova versão dispõe de endereços de 128 bits. Graças a esta ampliação, não será mais necessário utilizar soluções como a NAT e levará a uma completa e ilimitada conectividade para todas as máquinas atuais baseadas em IP, assim como para os novos dispositivos móveis como PDA e telefones celulares, que poderão dispor de acesso IP completo graças a GPRS e a UTMS.
9.1.7.2.2. Mobilidade
Quando se fala de dispositivos móveis e IP, um ponto importante a se ter presente é que é necessário um protocolo especial para suportar a mobilidade. A implementação deste protocolo, chamado IP móvel, é um dos requisitos de cada stack IPv6. Portanto, quando se ativa o IPv6 obtém-se o suporte para o roaming entre redes diferentes, com atualização completa quando se deixa uma rede e se transfere para uma outra. O suporte ao roaming é possível também com o IPv4, mas é preciso resolver alguns problemas antes de se obter um sistema que funcione. Com o IPv6 não é necessário nenhum artifício particular, uma vez que o suporte à mobilidade é um dos requisitos desse projeto. Ver [RFC3024] para maiores informações sobre os problemas a resolver para suportar o "IP móvel" no IPv4.
9.1.7.2.3. Segurança
Além do suporte para a mobilidade, a segurança era um dos requisitos do sucessor à atual versão do Internet Protocol. Como conseqüência, os stacks do protocolo IPv6 devem incluir o IPsec. O IPsec permite autenticar, criptografar e comprimir qualquer tipo de tráfico IP. Diferentemente dos protocolos em nível de aplicação, como o SSL ou o SSH, pode-se gerenciar todo o tráfico IP entre dois nódulos sem ter que fazer modificações nas próprias aplicações. A vantagem dessa abordagem é que todas as aplicações em uma máquina podem beneficiar-se da criptografia e da autenticação, e que as políticas correspondentes possam ser estabelecidas, de modo geral, no nível do host ou até mesmo da rede, e não simplesmente no nível do aplicativo/serviço. Uma introdução ao IPsec que compreende também os links com a documentação pode-se encontrar em [RFC2411], enquanto que o protocolo de base é descrito em [RFC2401].
9.1.7.3. Modificações no IPv4
Agora que vimos as várias características importantes do IPv6, podemos passar ao exame das bases do protocolo. Para uma melhor compreensão é preferível um conhecimento elementar do IPv4, em comparação com o qual serão descritas as diferenças. Comecemos com os endereços IPv6, explicando como estão estruturados, quais são os tipos de endereço e o que foi feito dos broadcasts. Assim, depois de ter discutido o "substrato" do IP, passaremos às mudanças relativas à resolução dos nomes e às novidades do IPv6 para o DNS.
9.1.7.3.1. Endereçamento
Um endereço IPv4 é um valor de 32 bits, escrito usualmente no formato "dotted quad", onde cada um dos valores separados por pontos é um valor compreendido entre 0 e 255. Por exemplo:
127.0.0.1
Esta estrutura permite um número máximo teórico de 232 ou ~4 bilhões de hosts serem conectados à atual Internet. Por causa dos agrupamentos, todavia, nem todos os endereços estão realmente disponíveis.
Os endereços IPv6 usam 128 bits, que nos levam a 2128 de hosts teoricamente endereçáveis. Isto permite endereçar um número verdadeiramente enorme de máquinas, cobrindo completamente sem problemas todos os requisitos atuais e futuros mesmo de PDAs e telefones celulares dotados de endereço IP. Para escrever os endereços IP, dividimo-os em grupos de 16 bits escritos com quatro algarismos hexadecimais, separando os grupos com o caracter ":" (dois pontos). Por exemplo:
fe80::2a0:d2ff:fea5:e9f5
Este exemplo mostra também que uma série de zeros consecutivos pode ser abreviada com um único "::" no endereço IPv6. O endereço precedente é pois equivalente a fe80:0:00:000:2a0:d2ff:fea5:e9f5. Os zeros iniciais dentro do grupo podem ser omitidos.
Para simplificar o gerenciamento, os endereços são divididos em duas partes: os bits que identificam a rede a que a máquina pertence e os bits que identificam a própria máquina na (sub)rede. Os primeiros são definidos como "bits de rede" (netbits) os segundos como "bits de host" (hostbits) e, tanto no IPv4 quanto no IPv6, os bits de rede são os que estão mais à esquerda (bits mais significativos), enquanto que os bits de host estão mais à direita (bits menos significativos), como se mostra na Figura 9-3.

No IPv4 os bits de rede e os bits de host são separados graças à máscara de rede. Exemplos típicos são 255.255.0.0, que usa 16 bits para o endereço de rede, e 255.255.255.0, que usa outros 8 bits, permitindo, por exemplo, endereçar 256 sub-redes em uma rede de classe B.
Quando se passa do endereçamento por classes ao formato CIDR, a separação entre bits de rede e bits de host deixa de cair necessariamente sobre o limite dos 8 bits e, por conseqüência, as máscaras de rede começam a ficar mais difíceis de gerenciar. No lugar das máscaras já se começa a indicar o limite usando o número de bits de rede para um dado endereço. Por exemplo:
10.0.0.0/24
corresponde a uma máscara de rede de 255.255.255.0 (24 bits por 1). O mesmo esquema é usado no IPv6. O valor:
2001:638:a01:2::/64
indica que no endereço especificado os primeiros 64 bits (os que estão mais à esquerda) dizem respeito à rede, enquanto os últimos 64 bits (os mais à direita) identificam a máquina na rede. Os bits de rede são freqüentemente chamados "prefixo" (da rede) e aqui o comprimento do prefixo é de 64 bits.
Entre os esquemas de endereçamento mais comuns do IPv4, estavam as redes de classe B e de classe C. Com uma rede de classe C (/24) o provedor atribui 24 bits, deixando 8 bits disponíveis. Se acrescentamos as sub-redes acaba-se tendo uma máscara de rede "irregular" não muito prática de se administrar. Neste caso uma rede de classe B (/16) seria mais fácil de administrar porque são fixados só 16 bits pelo provedor, o que permite criar sub-redes com mais facilidade, dividindo em duas partes os restantes 16 bits. A primeira parte endereça a sub-rede local e a segunda endereça o host no interior da própria sub-rede. Geralmente se "interrompe" no extremo dos oito bits (um byte). Usando uma máscara de rede de 255.255.255.0 (/24) consegue-se administrar de modo mais flexível mesmo redes de grandes dimensões, continuando-se a manter o limite de 256 sub-redes com 254 máquinas cada uma.
Com os 128 bits disponíveis para o endereçamento IPv6, o esquema utilizado é o mesmo, apenas que com os campos maiores. Os provedores usualmente estabelecem redes /48, o que deixa 16 bits para as sub-redes e 64 bits para os hosts.
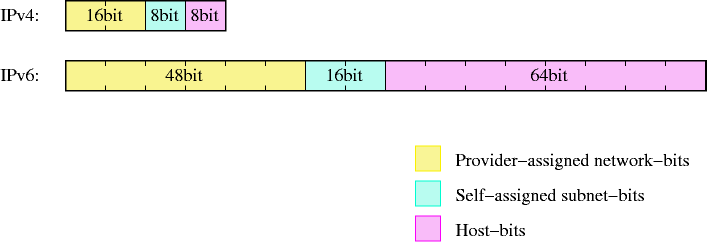
Enquanto o espaço para as rede e as sub-redes parece adequado, o uso de 64 bits para os hosts parece um desperdício de espaço. Visto que é improvável a utilização de vários bilhões de hosts na mesma sub-rede, porque usar essa estrutura?
A idéia que está na base de um identificador de host de comprimento fixo de 64 bits é que os identificadores de host não são mais estabelecidos manualmente, como é feito hoje com o IPv4. No lugar disso, recomenda-se (é só uma recomendação, não uma obrigação) contruí-los partindo dos assim chamados endereços EUI64. Os endereços EUI64 ocupam, como diz o nome, 64 bits e derivam do endereço MAC da placa de rede. Por exemplo, para a Ethernet, ao endereço de rede de 6 bytes (42 bits) são usualmente acrescentados os bits "fffe" no meio e um bit é definido para indicar que o endereço é único (o que é verdadeiro para a Ethernet). Por exemplo, o endereço MAC
01:23:45:67:89:ab
torna-se o endereço EUI64
03:23:45:ff:fe:67:89:ab
o que leva os bits de host do endereço IPv6 a ter a forma
::0323:45ff:fe67:89ab
Estes bits de host podem ser usados para designar o endereço IPv6 a um host suportando a auto-configuração dos hosts IPv6. Tudo o que é preciso para se ter um endereço IPv6 completo são os primeiros bits (rede/sub-rede), mas o IPv6 oferece ainda o sistema para determiná-los automaticamente.
Nas redes de máquinas IP há geralmente um router que age como gateway para com a redes externas. Nas redes IPv6 o router envia uma série de informações de "router advertisement", que os clientes deveriam receber enquanto estão em funcionamento ou solicitar explicitamente enquanto estão em fase de inicialização. Estas informações compreendem o endereço do router e os prefixos de rede geridos pelo próprio router. Com estas informações e o endereço EUI64 gerado automaticamente, um host IPv6 pode determinar seu próprio endereço IP sem uma atribuição manual. Naturalmente os routers devem ainda ser explicitamente configurados.
As informações enviadas pelo router fazem parte do protocolo NDP Neighbor Discovery Protocol (ver [RFC2461]), que é o sucessor do protocolo ARP do IPv4. Diferentemente do ARP, o NDP não apenas busca os endereços IP correspondentes aos endereços MAC, mas efetua também um serviço parecido para os routers e seus prefixos correspondentes das redes geridas, o que é utilizado pela auto-configuração dos hosts IPv6 recém descritos.
9.1.7.3.2. Endereços múltiplos
Com o IPv4, um host tem geralmente um endereço IP para cada interface de rede ou, se o stack o suporta, até mesmo por máquina. Somente alguns aplicativos específicos, como os servidores web, exigem máquinas que têm mais de um endereço IP. Com o IPv6, tudo isso é diferente. Para cada interface, não só há um endereço global, mas também dois outros endereços interessantes: o endereço "link local" e o endereço "site local". O endereço link local tem prefixo fe80::/64 e os bits de host derivam do endereço EUI64: é usado só para contactar os hosts e os routers da mesma rede e não é visível ou alcançável a partir de outras sub-redes. Se assim o desejarmos, pode-se escolher entre usar endereços globais (designados pelo provedor) ou endereços site local. Estes últimos têm o endereço de rede fex0::/10 e as sub-redes e os hosts podem ser endereçados exatamente como no caso das redes designadas pelo provedor. A única diferença é que o endereço não será visível pelas máquinas externas porque se encontram em uma rede diferente e seus endereços site local, se existem, estão em uma rede física diferente. Para o IPv6 é prática comum atribuir aos hosts o endereço global e o endereço link local. Os endereços site local estão-se tornando cada vez mais raros. Até porque para a conectividade global é exigido um endereço global único.
9.1.7.3.3. Multicasting
No domínio IP há três modos para se atingir um host: unicast, broadcast e multicast. A forma mais comum de conversação usufrui do endereço unicast que, no IPv4, é o endereço IP "normal" atribuído a um host, compreendendo os bits de rede. O endereço de broadcast é utilizado para se alcançar todos os hosts da mesma sub-rede IP e tem os bits de rede definidos pelo endereço da rede e os bits de host todos em "1". Os endereços de tipo multicast servem para se atingir os hosts que fazem parte do grupo multicast, que se podem encontrar em um ponto qualquer da Internet. As máquinas devem unir-se explicitamente a um grupo multicast para poder participar e há endereços especiais IPv4 usados para o multicast, alocados na sub-rede 224/8. O multicast não é muito utilizado sob o IPv4. Apenas alguns aplicativos como os utilitários MBone de áudio e vídeo broadcast o usam.
Os endereços unicast IPv6 são usados do mesmo modo que os IPv4. Não há nenhuma mudança. Assim, todos os bits de rede e de host são designados para identificar a rede e a máquina. O broadcast não está mais disponível em IPv6, do modo em que o era no IPv4. É aqui que entra em jogo o multicasting. Os endereços da rede ff::/8 são reservados para as aplicações multicast e há dois endereços multicast especiais que tomam o lugar do endereço de broadcast do IPv4. Um é o endereço multicast " all routers" (todos os estradadores) e o outro é o "all hosts" (todos os hospedeiros). Estes endereços são específicos da sub-rede. Ou seja, um router conectado a duas sub-redes pode endereçar todos os hosts/routers de qualquer uma das duas sub-redes. Nesse caso os endereços são:
ff0X::1 para todos os hosts
ff0X::2 para todos os routers
onde "X" é o ID da conexão que identifica a rede e que, geralmente, é iniciado em "1" para o âmbito local, em "2" para o primeiro link, etc. Note-se que é possível que duas interfaces de rede sejam vinculadas ao mesmo link, resultando na duplicação da amplitude da rede.
Um uso do endereço de multicast "all hosts" está no código NDP, quando uma máquina que se quer comunicar com uma outra máquina envia uma solicitação ao grupo all hosts e a máquina em questão deve responder.
9.1.7.3.4. A resolução dos nomes em IPv6
Depois desta longa introdução ao endereçamento em IPv6, é lícito esperar que haja um modo para continuar a usar nomes para nos referirmos aos hosts, como se faz com o IPv4, no lugar de desfiar os longos endereços IPv6. Naturalmente é possível.
A tradução do nome de host para o endereço IP em IPv4 geralmente se faz em um destes três modos: usando uma simples tabela no /etc/hosts, usando o Network Information Service (NIS, antes YP) ou com o Domain Name System (DNS).
No momento o NIS/NIS+ em IPv6 está disponível apenas para o Solaris 8, tanto para o conteúdo do banco de dados como para o transporte, usando uma extensão RPC.
Um simples mapa do tipo endereço<->nome, do tipo do /etc/hosts é suportado por todos os stacks IPv6. Com a implementação KAME usada no NetBSD, o arquivo /etc/hosts contém tanto os endereços IPv4 como os IPv6. A título de simples exemplo, vejamos a expressão "localhost" na versão default para uma instalação do NetBSD.
127.0.0.1 localhost ::1 localhost
Para o DNS não são introduzidos conceitos fundamentalmente novos. A resolução dos nomes IPv6 é feita com registro de tipo AAAA que, como indica o nome, apontam para uma entidade que é quatro vezes maior que um registro do tipo A. Um registro AAAA tem um nome de host na parte esquerda, do mesmo jeito que para A, e o endereço IPv6 na parte direita. Por exemplo:
noon IN AAAA 3ffe:400:430:2:240:95ff:fe40:4385
Para a resolução inversa o IPv4 usa a zona in-addr.arpa, à qual acrescenta os bytes (decimais) em ordem inversa, vale dizer com os bytes mais significativos mais à direita. Com o IPv6 o método é o mesmo, só que são usados os algarismos hexadecimais (um a cada 4 bits) ao invés dos números decimais e os registros dos recursos encontram-se em um domínio diferente: ip6.int.
Portanto, para a resolução inversa do host precedente, deve-se por no arquivo /etc/named.conf uma expressão parecida com a seguinte:
zone "0.3.4.0.0.0.4.0.e.f.f.3.IP6.INT" {
type master;
file "db.reverse";}; e, no arquivo de zona db.reverse, além dos usuais registros SOA e NS:
5.8.3.4.0.4.e.f.f.f.5.9.0.4.2.0.2.0.0.0 IN PTR noon.ipv6.example.com.
Aqui o endereço é escrito como uma cifra hexadecimal e, ao mesmo tempo, em ordem inversa, iniciando-se pela menos significativa (a que está mais à direita) e separando os números com pontos, como nos costumeiros arquivos de zona.
Quando se instala o DNS para o IPv6, é preciso prestar atenção à versão do software DNS que se utiliza. BIND 8.x compreende os registros AAAA mas não oferece a resolução dos nomes via IPv6. Porisso é necessário utilizar o BIND 9.x que, entre outras coisas, suporta alguns tipos de registro de recursos ainda em fase de discussão e, portanto, não introduzidos oficialmente. O mais interessante é o registro A6, que facilita a mudança do provedor/prefixo.
Resumindo, nesta seção foram discutidas as diferenças técnicas entre o IPv4 e o IPv6 para o endereçamento e resolução dos nomes. Alguns aspectos, como as opções dos títulos IP, QoS, etc. não foram intencionalmente tratados para não avolumar demais a matéria, dado também o caráter introdutório deste guia.
Bibliografia
[RFC1055] J. L. Romkey, 1988, RFC 1055: Nonstandard for transmission of IP datagrams over serial lines: SLIP.
[RFC1331] W. Simpson, 1992, RFC 1331: The Point-to-Point Protocol (PPP) for the Transmission of Multi-protocol Datagrams over Point-to-Point Links.
[RFC1933] R. Gilligan e E. Nordmark, 1996, RFC 1933: Transition Mechanisms for IPv6 Hosts and Routers.
[RFC2461] T. Narten, E. Nordmark, e W. Simpson, 1998, RFC 2461: Neighbor Discovery for IP Version 6 (IPv6).
[RFC2529] B. Carpenter e C. Jung, 1999, RFC 2529: Transmission of IPv6 over IPv4 Domains without Explicit Tunnels.